Tableau-Funktionen (nach Kategorie)
Die Tableau-Funktionen in dieser Referenz sind nach Kategorie organisiert. Klicken Sie auf eine Kategorie, um ihre Funktionen zu durchsuchen. Drücken Sie alternativ auf Strg+F (Befehlstaste-F auf einem Mac), um ein Suchfeld zu öffnen, das Sie verwenden können, um die Seite nach einer spezifischen Funktion zu durchsuchen.
ABS
| Syntax | ABS(number) |
| Ausgabe | Zahl (positiv) |
| Definition | Gibt den absoluten Wert der jeweiligen Zahl (<number>) zurück. |
| Beispiel | ABS(-7) = 7 Das zweite Beispiel gibt den absoluten Wert für alle im Feld "Budget Variance" (Budgetabweichung) enthaltenen Zahlen zurück. |
| Hinweise | Siehe auch SIGN. |
ACOS
| Syntax | ACOS(number) |
| Ausgabe | Zahl (Winkel im Bogenmaß) |
| Definition | Gibt den Arkuskosinus (Winkel) der gegebenen Zahl (<number>) zurück. |
| Beispiel | ACOS(-1) = 3.14159265358979 |
| Hinweise | Die Umkehrfunktion COS nimmt den Winkel im Bogenmaß als Argument und gibt den Kosinus zurück. |
ASIN
| Syntax | ASIN(number) |
| Ausgabe | Zahl (Winkel im Bogenmaß) |
| Definition | Gibt den Arkussinus (Winkel) einer gegebenen Zahl (<number>) zurück. |
| Beispiel | ASIN(1) = 1.5707963267949 |
| Hinweise | Die Umkehrfunktion SIN nimmt den Winkel im Bogenmaß als Argument und gibt den Sinus zurück. |
ATAN
| Syntax | ATAN(number) |
| Ausgabe | Zahl (Winkel im Bogenmaß) |
| Definition | Gibt den Arkustangens (Winkel) einer gegebenen Zahl (<number>) zurück. |
| Beispiel | ATAN(180) = 1.5652408283942 |
| Hinweise | Die Umkehrfunktion |
ATAN2
| Syntax | ATAN2(y number, x number) |
| Ausgabe | Zahl (Winkel im Bogenmaß) |
| Definition | Gibt den Arkustangens (Winkel) zwischen zwei Zahlen (x und y) zurück. Das Ergebnis wird im Bogenmaß (Radiant) angegeben. |
| Beispiel | ATAN2(2, 1) = 1.10714871779409 |
| Hinweise | Siehe auch ATAN, TAN und COT. |
CEILING
| Syntax | CEILING(number) |
| Ausgabe | Ganzzahl |
| Definition | Rundet eine Zahl (<number>) auf die nächste Ganzzahl desselben oder höheren Werts auf. |
| Beispiel | CEILING(2.1) = 3 |
| Hinweise | Siehe auch FLOOR und ROUND. |
| Datenbankseitige Einschränkungen |
|
COS
| Syntax | COS(number)Das Zahlenargument ist der Winkel im Bogenmaß. |
| Ausgabe | Zahl |
| Definition | Gibt den Kosinus eines Winkels zurück. |
| Beispiel | COS(PI( ) /4) = 0.707106781186548 |
| Hinweise | Die Umkehrfunktion Siehe auch |
COT
| Syntax | COT(number)Das Zahlenargument ist der Winkel im Bogenmaß. |
| Ausgabe | Zahl |
| Definition | Gibt den Kotangens eines Winkels zurück. |
| Beispiel | COT(PI( ) /4) = 1 |
| Hinweise | Siehe auch ATAN, TAN und PI. Um einen Winkel von Grad in Bogenmaß umzurechnen, verwenden Sie RADIANS. |
DEGREES
| Syntax | DEGREES(number)Das Zahlenargument ist der Winkel im Bogenmaß. |
| Ausgabe | Zahl (Grad) |
| Definition | Wandelt einen Winkel im Bogenmaß in Grad um. |
| Beispiel | DEGREES(PI( )/4) = 45.0 |
| Hinweise | Die Umkehrfunktion Siehe auch |
DIV
| Syntax | DIV(integer1, integer2) |
| Ausgabe | Ganzzahl |
| Definition | Gibt den Ganzzahl-Teil einer Division zurück, bei der <integer1> durch <integer2> geteilt wird. |
| Beispiel | DIV(11,2) = 5 |
EXP
| Syntax | EXP(number) |
| Ausgabe | Zahl |
| Definition | Gibt "e" potenziert mit der angegebenen Zahl (<number>) zurück. |
| Beispiel | EXP(2) = 7.389 |
| Hinweise | Siehe auch LN. |
FLOOR
| Syntax | FLOOR(number) |
| Ausgabe | Ganzzahl |
| Definition | Rundet eine Zahl auf die nächste Zahl (<number>) desselben oder eines niedrigeren Werts ab. |
| Beispiel | FLOOR(7.9) = 7 |
| Hinweise | Siehe auch CEILING und ROUND. |
| Datenbankseitige Einschränkungen |
|
HEXBINX
| Syntax | HEXBINX(number, number) |
| Ausgabe | Zahl |
| Definition | Ordnet eine x-, y-Koordinate der x-Koordinate der nächsten hexagonalen Partition zu. Die Partitionen verfügen über eine Seitenlänge von 1, daher müssen die Eingaben möglicherweise entsprechend skaliert werden. |
| Beispiel | HEXBINX([Longitude]*2.5, [Latitude]*2.5) |
| Hinweise | HEXBINX und HEXBINY sind Binning- und Plottingfunktionen für hexagonale Partitionen. Hexagonale Partitionen sind eine effiziente und elegante Möglichkeit, Daten in einer x-/y-Ebene, beispielsweise eine Karte, zu visualisieren. Da die Partitionen hexagonal sind, nähert sich jede Partition eng an einen Kreis an und minimiert die Variation in der Entfernung vom Datenpunkt zum Zentrum der Partition. Dadurch wird die Gruppierung genauer und aussagekräftiger. |
HEXBINY
| Syntax | HEXBINY(number, number) |
| Ausgabe | Zahl |
| Definition | Ordnet eine x-, y-Koordinate der y-Koordinate der nächsten hexagonalen Partition zu. Die Partitionen verfügen über eine Seitenlänge von 1, daher müssen die Eingaben möglicherweise entsprechend skaliert werden. |
| Beispiel | HEXBINY([Longitude]*2.5, [Latitude]*2.5) |
| Hinweise | Siehe auch HEXBINX. |
LN
| Syntax | LN(number) |
| Ausgabe | Zahl Die Ausgabe ist |
| Definition | Gibt den natürlichen Logarithmus einer Zahl (<number>) zurück. |
| Beispiel | LN(50) = 3.912023005 |
| Hinweise | Siehe auch EXP und LOG. |
LOG
| Syntax | LOG(number, [base])Wenn das optionale Basisargument nicht vorhanden ist, wird Basis 10 verwendet. |
| Ausgabe | Zahl |
| Definition | Gibt den Logarithmus einer Zahl zur Basis zurück. |
| Beispiel | LOG(16,4) = 2 |
| Hinweise | Siehe auch POWER LN. |
MAX
| Syntax | MAX(expression) oder MAX(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Maximalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MAX(4,7) = 7 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
MIN
| Syntax | MIN(expression) oder MIN(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Minimalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MIN(4,7) = 4 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
PI
| Syntax | PI() |
| Ausgabe | Zahl |
| Definition | Gibt die numerische Konstante Pi (Kreiszahl) zurück: 3,14159. |
| Beispiel | PI() = 3.14159 |
| Hinweise | Nützlich für Trig-Funktionen, deren Eingabe im Bogenmaß erfolgt. Siehe auch RADIANS. |
POWER
| Syntax | POWER(number, power) |
| Ausgabe | Zahl |
| Definition | Potenziert die Zahl (<number>) mit dem Exponenten (<power>). |
| Beispiel | POWER(5,3) = 125 |
| Hinweise | Sie können auch das Symbol ^ verwenden (z. B. 5^3 = POWER(5,3) = 125). |
RADIANS
| Syntax | RADIANS(number) |
| Ausgabe | Zahl (Winkel im Bogenmaß) |
| Definition | Wandelt eine in Grad angegebene Zahl (<number>) in Bogenmaß (Radiant) um. |
| Beispiel | RADIANS(180) = 3.14159 |
| Hinweise | Die Umkehrfunktion DEGREES nimmt einen Winkel im Bogenmaß und gibt den Winkel in Grad zurück. |
ROUND
| Syntax | ROUND(number, [decimals]) |
| Ausgabe | Zahl |
| Definition | Rundet eine Zahl ( Das optionale Argument |
| Beispiel | ROUND(1/3, 2) = 0.33 |
| Hinweise | Einige Datenbanken wie SQL Server ermöglichen die Angabe einer negativen Länge, wobei -1 Zahlen auf 10er, -2 Zahlen auf 100er usw. rundet. Dies trifft nicht auf alle Datenbanken zu. Es gilt beispielsweise nicht für Excel oder Access. Tipp: Da |
SIGN
| Syntax | SIGN(number) |
| Ausgabe | -1, 0 oder 1 |
| Definition | Gibt das Vorzeichen einer Zahl (<number>) zurück. Die folgenden Rückgabewerte sind möglich: -1, wenn die Zahl negativ ist; 0, wenn die Zahl 0 (null) ist; 1, wenn die Zahl positiv ist. |
| Beispiel | SIGN(AVG(Profit)) = -1 |
| Hinweise | Siehe auch ABS. |
SIN
| Syntax | SIN(number)Das Zahlenargument ist der Winkel im Bogenmaß. |
| Ausgabe | Zahl |
| Definition | Gibt den Sinus eines Winkels zurück. |
| Beispiel | SIN(0) = 1.0 |
| Hinweise | Die Umkehrfunktion Siehe auch |
SQRT
| Syntax | SQRT(number) |
| Ausgabe | Zahl |
| Definition | Gibt die Quadratwurzel einer Zahl (<number>) zurück. |
| Beispiel | SQRT(25) = 5 |
| Hinweise | Siehe auch SQUARE. |
SQUARE
| Syntax | SQUARE(number) |
| Ausgabe | Zahl |
| Definition | Gibt das Quadrat einer Zahl (<number>) zurück. |
| Beispiel | SQUARE(5) = 25 |
| Hinweise | Siehe auch SQRT und POWER. |
TAN
| Syntax | TAN(number)Das Zahlenargument ist der Winkel im Bogenmaß. |
| Ausgabe | Zahl |
| Definition | Gibt den Tangens eines Winkels zurück. |
| Beispiel | TAN(PI ( )/4) = 1.0 |
| Hinweise | Siehe auch ATAN, ATAN2,COT und PI. Um einen Winkel von Grad in Bogenmaß umzurechnen, verwenden Sie RADIANS. |
ZN
| Syntax | ZN(expression) |
| Ausgabe | Beliebig oder 0 |
| Definition | Gibt den Ausdruck ( Verwenden Sie diese Funktion, um Null-Werte durch Nullen zu ersetzen. |
| Beispiel | ZN(Grade) = 0 |
| Hinweise | Dies ist eine sehr nützliche Funktion, wenn in einer Berechnung Felder verwendet werden, die möglicherweise Nullen enthalten. Das Einschließen des Felds in ZN kann Fehler verhindern, die durch die Berechnung mit Nullen entstehen. |
ASCII
| Syntax | ASCII(string) |
| Ausgabe | Zahl |
| Definition | Gibt den ASCII-Code für das erste Zeichen einer Zeichenfolge (<string>) zurück. |
| Beispiel | ASCII('A') = 65 |
| Hinweise | Dies ist die Umkehrfunktion von CHAR. |
CHAR
| Syntax | CHAR(number) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt das Zeichen zurück für die ASCII-codierte <number>. |
| Beispiel | CHAR(65) = 'A' |
| Hinweise | Dies ist die Umkehrfunktion von ASCII. |
CONTAINS
| Syntax | CONTAINS(string, substring) |
| Ausgabe | Boolesch |
| Definition | Gibt TRUE zurück, wenn die Zeichenfolge die angegebene Teilzeichenfolge enthält. |
| Beispiel | CONTAINS("Calculation", "alcu") = true |
| Hinweise | Siehe auch die logische Funktion(Link wird in neuem Fenster geöffnet) IN sowie unterstützte RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
ENDSWITH
| Syntax | ENDSWITH(string, substring) |
| Ausgabe | Boolesch |
| Definition | Gibt TRUE zurück, wenn die Zeichenfolge mit der angegebenen Teilzeichenfolge endet. Nachfolgende Leerzeichen werden ignoriert. |
| Beispiel | ENDSWITH("Tableau", "leau") = true |
| Hinweise | Siehe auch die unterstützten RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
FIND
| Syntax | FIND(string, substring, [start]) |
| Ausgabe | Zahl |
| Definition | Gibt die Index-Position einer Teilzeichenfolge in einer Zeichenfolge zurück, oder 0, wenn die Teilzeichenfolge nicht gefunden wird. Das erste Zeichen in der Zeichenfolge ist Position 1. Wenn das optionale numerische Argument |
| Beispiel | FIND("Calculation", "alcu") = 2FIND("Calculation", "Computer") = 0FIND("Calculation", "a", 3) = 7FIND("Calculation", "a", 2) = 2FIND("Calculation", "a", 8) = 0 |
| Hinweise | Siehe auch die unterstützten RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
FINDNTH
| Syntax | FINDNTH(string, substring, occurrence) |
| Ausgabe | Zahl |
| Definition | Gibt die Position des n-ten Vorkommens einer Unterzeichenfolge in einer angegebenen Zeichenfolge zurück, wobei n durch das Argument "occurrence" definiert wird. |
| Beispiel | FINDNTH("Calculation", "a", 2) = 7 |
| Hinweise |
Siehe auch die unterstützten RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
LEFT
| Syntax | LEFT(string, number) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt den linken Teil einer Zeichenfolge mit der angegebenen Anzahl an Zeichen (<number>) zurück. |
| Beispiel | LEFT("Matador", 4) = "Mata" |
| Hinweise | Siehe auch MID und RIGHT. |
LEN
| Syntax | LEN(string) |
| Ausgabe | Zahl |
| Definition | Gibt die Länge der Zeichenfolge zurück. |
| Beispiel | LEN("Matador") = 7 |
| Hinweise | Nicht zu verwechseln mit der räumlichen Funktion(Link wird in neuem Fenster geöffnet) LENGTH. |
LOWER
| Syntax | LOWER(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die bereitgestellte <string> in Kleinbuchstaben zurück. |
| Beispiel | LOWER("ProductVersion") = "productversion" |
| Hinweise | Siehe auch UPPER und PROPER. |
LTRIM
| Syntax | LTRIM(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die bereitgestellte Zeichenfolge (<string>) zurück und entfernt dabei alle vorangestellten Leerzeichen. |
| Beispiel | LTRIM(" Matador ") = "Matador " |
| Hinweise | Siehe auch RTRIM. |
MAX
| Syntax | MAX(expression) oder MAX(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Maximalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MAX(4,7) = 7 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
MID
| Syntax | (MID(string, start, [length]) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt eine Zeichenfolge zurück, die an der angegebenen Wird das optionale numerische Argument |
| Beispiel | MID("Calculation", 2) = "alculation"MID("Calculation", 2, 5) ="alcul" |
| Hinweise | Siehe auch die unterstützten RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
MIN
| Syntax | MIN(expression) oder MIN(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Minimalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MIN(4,7) = 4 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
PROPER
| Syntax | PROPER(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die angegebene Zeichenfolge ( |
| Beispiel | PROPER("PRODUCT name") = "Product Name"PROPER("darcy-mae") = "Darcy-Mae" |
| Hinweise | Leerzeichen und nicht-alphanumerische Zeichen (z. B. Interpunktionszeichen) werden als Trennzeichen behandelt. |
| Datenbankseitige Einschränkungen | PROPER ist nur für einige Flatfiles und in Auszügen verfügbar. Wenn Sie PROPER in einer Datenquelle verwenden müssen, die dies ansonsten nicht unterstützt, sollten Sie die Verwendung eines Extrakts in Betracht ziehen. |
REPLACE
| Syntax | REPLACE(string, substring, replacement |
| Ausgabe | Zeichenfolge |
| Definition | Sucht nach <string> für <substring> und ersetzt diesen durch <replacement>. Falls die <substring> nicht gefunden wird, bleibt die Zeichenfolge unverändert. |
| Beispiel | REPLACE("Version 3.8", "3.8", "4x") = "Version 4x" |
| Hinweise | Siehe auch REGEXP_REPLACE in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
RIGHT
| Syntax | RIGHT(string, number) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt den rechten Teil einer Zeichenfolge mit der angegebenen Anzahl an Zeichen (<number>) zurück. |
| Beispiel | RIGHT("Calculation", 4) = "tion" |
| Hinweise | Siehe auch LEFT und MID. |
RTRIM
| Syntax | RTRIM(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die bereitgestellte Zeichenfolge (<string>) zurück und entfernt dabei alle nachgestellten Leerzeichen. |
| Beispiel | RTRIM(" Calculation ") = " Calculation" |
| Hinweise | Siehe auch LTRIM und TRIM. |
SPACE
| Syntax | SPACE(number) |
| Ausgabe | Zeichenfolge (eigentlich nur Leerzeichen) |
| Definition | Gibt eine Zeichenfolge zurück, die aus der angegebenen Anzahl an Leerzeichen besteht. |
| Beispiel | SPACE(2) = " " |
SPLIT
| Syntax | SPLIT(string, delimiter, token number) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt eine Unterzeichenfolge von einer Zeichenfolge zurück und unterteilt die Zeichenfolge anhand von Trennzeichen in eine Abfolge aus Token. |
| Beispiel | SPLIT ("a-b-c-d", "-", 2) = "b"SPLIT ("a|b|c|d", "|", -2) = "c" |
| Hinweise | Die Zeichenfolge wird als eine sich abwechselnde Sequenz aus Trennzeichen und Token interpretiert. Bei der Zeichenfolge
Siehe auch unterstützte REGEX in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
| Datenbankseitige Einschränkungen | Die Befehle "Teilen" und "Benutzerdefiniertes Teilen" stehen für die folgenden Datenquellentypen zur Verfügung: Tableau-Datenextrakte, Microsoft Excel, Textdatei, PDF-Datei, Salesforce, OData, Microsoft Azure Market Place, Google Analytics, Vertica, Oracle, MySQL, PostgreSQL, Teradata, Amazon Redshift, Aster Data, Google Big Query, Cloudera Hadoop Hive, Hortonworks Hive und Microsoft SQL Server. Einige Datenquellen setzen Limits in Bezug auf das Aufteilen einer Zeichenfolge. Weitere Informationen dazu finden Sie unter den Einschränkungen der SPLIT-Funktion weiter unten. |
STARTSWITH
| Syntax | STARTSWITH(string, substring) |
| Ausgabe | Boolesch |
| Definition | Gibt "true" zurück, wenn string mit substring beginnt. Vorgestellte Leerzeichen werden ignoriert. |
| Beispiel | STARTSWITH("Matador, "Ma") = TRUE |
| Hinweise | Siehe auch CONTAINS sowie unterstützte REGEX in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
TRIM
| Syntax | TRIM(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die bereitgestellte Zeichenfolge (<string>) zurück und entfernt dabei alle vor- und nachgestellten Leerzeichen. |
| Beispiel | TRIM(" Calculation ") = "Calculation" |
| Hinweise | Siehe auch LTRIM und RTRIM. |
UPPER
| Syntax | UPPER(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die angegebene Zeichenfolge (<string>) in Großbuchstaben zurück. |
| Beispiel | UPPER("Calculation") = "CALCULATION" |
| Hinweise | Siehe auch PROPER und LOWER. |
Viele Datumsfunktionen in Tableau nehmen das Argument date_part entgegen, das eine Zeichenfolgenkonstante ist, die der Funktion mitteilt, welcher Teil eines angegebenen Datums berücksichtigt werden soll (z. B. der Tag, die Woche, das Quartal usw.). Die gültigen date_part-Werte, die Sie verwenden können, sind:
| date_part | Werte |
|---|---|
'year' | Jahr mit vier Ziffern |
'quarter' | 1–4 |
'month' | 1–12 oder "Januar", "Februar"usw. |
'dayofyear' | Tag des Jahres, Jan 1 = 1, Feb 1 = 32 usw. |
'day' | 1–31 |
'weekday' | 1–7 oder "Sonntag", "Montag"usw. |
'week' | 1–52 |
'hour' | 0–23 |
'minute' | 0–59 |
'second' | 0–60 |
'iso-year' | Vierstellige Jahresangaben nach ISO 8601 |
'iso-quarter' | 1–4 |
'iso-week' | 1–52, Wochenstart ist immer am Montag |
'iso-weekday' | 1–7, Wochenstart ist immer am Montag |
Hinweis: Datumsfunktionen werden vom konfigurierten Geschäftsjahresbeginn nicht berücksichtigt. Siehe Datumsangaben für Geschäftszeiträume.
DATE
Eine Typumwandlungsfunktion, die Zeichenfolgen- und Zahlenausdrücke in Datumswerte ändert, sofern diese in einem erkennbaren Format angegeben sind.
| Syntax | DATE(expression) |
| Ausgabe | Datum |
| Definition | Gibt für eine Zahl, eine Zeichenfolge oder einen Datumsausdruck <expression> ein Datum zurück. |
| Beispiel | DATE([Employee Start Date]) DATE("September 22, 2018") DATE("9/22/2018")DATE(#2018-09-22 14:52#) |
| Hinweise | Im Gegensatz zu
|
DATEADD
Fügt einem Teil (date_part) des Startdatum (date) ein angegebenes zeitliches Intervall (Anzahl von Monaten, Tagen usw.) hinzu.
| Syntax | DATEADD(date_part, interval, date) |
| Ausgabe | Datum |
| Definition | Gibt das <date> mit zum festgelegten Datumsbereich <date_part> hinzugefügtem festgelegtem Zahlenintervall <interval> zurück. Beispiel: Einem Startdatum werden drei Monate oder 12 Tage hinzugefügt. |
| Beispiel | Aufschieben aller Fälligkeitstermine um eine Woche DATEADD('week', 1, [due date])Hinzufügen von 280 Tagen zum Datum "20. Februar 2021" DATEADD('day', 280, #2/20/21#) = #November 27, 2021# |
| Hinweise | Datumsangaben nach ISO 8601 werden unterstützt. |
DATEDIFF
Gibt die Anzahl von Datumsteilen (Wochen, Jahr usw.) zurück, die zwischen zwei angegebenen Datumswerten liegen.
| Syntax | DATEDIFF(date_part, date1, date2, [start_of_week]) |
| Ausgabe | Ganzzahl |
| Definition | Gibt die Differenz zwischen <date1> und <date2n> zurück und verwendet dabei die Einheit von <date_part>. Beispiel: Zwei Datumsangaben sollen subtrahiert werden, um zu sehen, wie lange jemand in einer Band war. |
| Beispiel | Die Anzahl der Tage zwischen dem 25. März 1986 und dem 20. Februar 2021 DATEDIFF('day', #3/25/1986#, #2/20/2021#) = 12,751Wie viele Monate jemand in einer Band war DATEDIFF('month', [date joined band], [date left band]) |
| Hinweise | Datumsangaben nach ISO 8601 werden unterstützt. |
DATENAME
Gibt den Namen des angegebenen Datumsteils als einzelne Zeichenfolge zurück.
| Syntax | DATENAME(date_part, date, [start_of_week]) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt <date_part> von <date> als Zeichenfolge zurück. |
| Beispiel | DATENAME('year', #3/25/1986#) = "1986"DATENAME('month', #1986-03-25#) = "March" |
| Hinweise | Datumsangaben nach ISO 8601 werden unterstützt. Eine sehr ähnliche Berechnung ist DATEPART, das den Wert des angegebenen Datumsteils als fortlaufende Ganzzahl zurückgibt. Indem Sie die Attribute des Ergebnisses der Berechnungen (Dimension oder Kennzahl, fortlaufend oder einzeln) und die Formatierung des Datums ändern, können die Ergebnisse von Eine inverse Funktion ist DATEPARSE, welche einen Zeichenfolgenwert entgegennimmt und diesen dann als ein Datum formatiert. |
DATEPARSE
Gibt speziell formatierte Zeichenfolgen Datum zurück.
| Syntax | DATEPARSE(date_format, date_string) |
| Ausgabe | Datum |
| Definition | Das Argument <date_format> beschreibt, wie das Feld <date_string> angeordnet wird. Da das Zeichenfolgenfeld auf die unterschiedlichsten Weisen sortiert werden kann, muss <date_format> genau übereinstimmen. Eine vollständige Erklärung finden Sie unter Konvertieren eines Feldes in ein Datumsfeld(Link wird in neuem Fenster geöffnet). |
| Beispiel | DATEPARSE('yyyy-MM-dd', "1986-03-25") = #March 25, 1986# |
| Hinweise |
Inverse Funktionen, die ein Datum zerlegen und den Wert einzelner Teile zurückgeben, sind |
| Datenbankseitige Einschränkungen |
|
DATEPART
Gibt den Namen des angegebenen Datumsteils als eine Ganzzahl zurück.
| Syntax | DATEPART(date_part, date, [start_of_week]) |
| Ausgabe | Ganzzahl |
| Definition | Gibt <date_part> von <date> als ganze Zahl zurück. |
| Beispiel | DATEPART('year', #1986-03-25#) = 1986DATEPART('month', #1986-03-25#) = 3 |
| Hinweise | Datumsangaben nach ISO 8601 werden unterstützt. Eine sehr ähnliche Berechnung ist Eine inverse Funktion ist |
DATETRUNC
Diese Funktion kann man sich als eine Rundung des Datums vorstellen. Sie nimmt ein bestimmtes Datum entgegen und gibt eine Version dieses Datums zurück, die auf der angegebenen Ebene liegt. Da jedes Datum einen Wert für Tag, Monat, Quartal und Jahr haben muss, legt DATETRUNC die Werte als niedrigsten Wert für jeden Datumsteil bis zu dem angegebenen Datum fest. Weitere Informationen finden Sie in dem Beispiel.
| Syntax | DATETRUNC(date_part, date, [start_of_week]) |
| Ausgabe | Datum |
| Definition | Kürzt das angegebene Datum <date> auf die durch den Datumsteil (<date_part>) angegebene Genauigkeit. Diese Funktion gibt ein neues Datum zurück. Wenn Sie beispielsweise ein Datum, das in der Mitte eines Monats liegt, auf Monatsebene verkürzen, gibt diese Funktion den ersten Tag des Monats zurück. |
| Beispiel | DATETRUNC('day', #9/22/2018#) = #9/22/2018#DATETRUNC('iso-week', #9/22/2018#) = #9/17/2018#(Der Montag der Woche, in der der 22.09.2018 liegt) DATETRUNC(quarter, #9/22/2018#) = #7/1/2018# (Der erste Tag des Quartal, in dem der 22.09.2018 liegt) Hinweis: Bei Woche und ISO-Woche kommt der Wochenanfang ( |
| Hinweise | Datumsangaben nach ISO 8601 werden unterstützt. Sie sollten So würde zum Beispiel |
DAY
Gibt den Tag des Monats als Ganzzahl (1–31) zurück.
| Syntax | DAY(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt den Tag des angegebenen Datums <date> als Ganzzahl zurück. |
| Beispiel | Day(#September 22, 2018#) = 22 |
| Hinweise | Siehe auch WEEK, MONTH, QUARTER, YEAR und die ISO-Äquivalente. |
ISDATE
Überprüft, ob die Zeichenfolge ein gültiges Datumsformat ist.
| Syntax | ISDATE(string) |
| Ausgabe | Boolesch |
| Definition | Gibt "true" zurück, wenn eine angegebene Zeichenfolge (<string>) ein gültiges Datum darstellt. |
| Beispiel | ISDATE(09/22/2018) = true ISDATE(22SEP18) = false |
| Hinweise | Das erforderliche Argument muss eine Zeichenfolge sein. ISDATE kann nicht für ein Feld von einem Datentyp "Datum" verwendet werden – die Berechnung würde eine Fehler zurückgeben. |
ISOQUARTER
| Syntax | ISOQUARTER(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt das auf der ISO8601-Woche basierende Quartal eines bestimmten Datums (<date>) als Ganzzahl zurück. |
| Beispiel | ISOQUARTER(#1986-03-25#) = 1 |
| Hinweise | Siehe auch ISOWEEK, ISOWEEKDAY, ISOYEAR und die Nicht-ISO-Äquivalente. |
ISOWEEK
| Syntax | ISOWEEK(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt die auf der ISO8601-Woche basierende Woche eines bestimmten Datums (<date>) als Ganzzahl zurück. |
| Beispiel | ISOWEEK(#1986-03-25#) = 13 |
| Hinweise | Siehe auch ISOWEEKDAY, ISOQUARTER, ISOYEAR und die Nicht-ISO-Äquivalente. |
ISOWEEKDAY
| Syntax | ISOWEEKDAY(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt den auf der ISO8601-Woche basierenden Wochentag eines bestimmten Datums (<date>) als Ganzzahl zurück. |
| Beispiel | ISOWEEKDAY(#1986-03-25#) = 2 |
| Hinweise | Siehe auch ISOWEEK, ISOQUARTER, ISOYEAR und die Nicht-ISO-Äquivalente. |
ISOYEAR
| Syntax | ISOYEAR(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt das auf der ISO8601-Woche basierende Jahr eines bestimmten Datums ( <date> ) als Ganzzahl zurück. |
| Beispiel | ISOYEAR(#1986-03-25#) = 1,986 |
| Hinweise | Siehe auch ISOWEEK, ISOWEEKDAY, ISOQUARTER und die Nicht-ISO-Äquivalente. |
MAKEDATE
| Syntax | MAKEDATE(year, month, day) |
| Ausgabe | Datum |
| Definition | Gibt einen Datumswert zurück, der aus dem angegebenen <year>, <monthg> und <day> gebildet wird. |
| Beispiel | MAKEDATE(1986,3,25) = #1986-03-25# |
| Hinweise | Anmerkung: Fehlerhaft eingegebene Werte werden so angepasst, dass sie ein Datum ergeben. So würde zum Beispiel Ist für Extrakte verfügbar. Prüfen Sie die Verfügbarkeit in anderen Datenquellen.
|
MAKEDATETIME
| Syntax | MAKEDATETIME(date, time) |
| Ausgabe | Datum/Uhrzeit |
| Definition | Gibt einen Datum/Zeit-Wert zurück, der ein Datum (<date>) und eine Uhrzeit (<time>) kombiniert. Das Datum kann den Datentyp Datum, Datum/Zeit oder Zeichenfolge haben. Die Uhrzeit muss ein Datum/Zeit-Wert sein. |
| Beispiel | MAKEDATETIME("1899-12-30", #07:59:00#) = #12/30/1899 7:59:00 AM#MAKEDATETIME([Date], [Time]) = #1/1/2001 6:00:00 AM# |
| Hinweise | Diese Funktion ist nur für MySQL-kompatible Verbindungen verfügbar (für Tableau wären das MySQL und Amazon Aurora).
|
MAKETIME
| Syntax | MAKETIME(hour, minute, second) |
| Ausgabe | Datum/Uhrzeit |
| Definition | Gibt einen Datumswert zurück, der aus den angegebenen Werten für <hour>, <minute> und <second> gebildet wird. |
| Beispiel | MAKETIME(14, 52, 40) = #1/1/1899 14:52:40# |
| Hinweise | Da Tableau nicht den Datentyp "Uhrzeit" unterstützt, sondern nur "Datum/Uhrzeit"(datetime), ist die Ausgabe ein Wert im Format "Datum+Uhrzeit". Im Datumsteil des Feldes wird "01.01.1899" stehen. Ähnliche Funktion wie |
MAX
| Syntax | MAX(expression) oder MAX(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL, wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Maximalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MAX(4,7) = 7 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
MIN
| Syntax | MIN(expression) oder MIN(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Minimalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MIN(4,7) = 4 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
MONTH
| Syntax | MONTH(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt den Monat des angegebenen Datums <date> als Ganzzahl zurück. |
| Beispiel | MONTH(#1986-03-25#) = 3 |
| Hinweise | Siehe auch DAY, WEEK, QUARTER, YEAR und die ISO-Äquivalente |
NOW
| Syntax | NOW() |
| Ausgabe | Datum/Uhrzeit |
| Definition | Gibt das aktuelle lokale Systemdatum und die Uhrzeit zurück. |
| Beispiel | NOW() = 1986-03-25 1:08:21 PM |
| Hinweise |
Siehe auch Wenn die Verbindung eine Direktverbindung ist, könnten das Systemdatum- und -uhrzeit aus einer anderen Zeitzone stammen. Weitere Informationen dazu, wie mit solchen Fällen umgegangen wird, finden Sie in der Knowledgebase. |
QUARTER
| Syntax | QUARTER(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt das Quartal des angegebenen Datums <date> als Ganzzahl zurück. |
| Beispiel | QUARTER(#1986-03-25#) = 1 |
| Hinweise | Siehe auch DAY, WEEK, MONTH, YEAR und die ISO-Äquivalente |
TODAY
| Syntax | TODAY() |
| Ausgabe | Datum |
| Definition | Gibt das aktuelle lokale Systemdatum zurück. |
| Beispiel | TODAY() = 1986-03-25 |
| Hinweise |
Siehe auch NOW, eine ähnliche Berechnung, die ein Datum/Uhrzeit anstatt eines Datums zurückgibt. Wenn die Verbindung eine Direktverbindung ist, könnte das Systemdatum aus einer anderen Zeitzone stammen. Weitere Informationen dazu, wie mit solchen Fällen umgegangen wird, finden Sie in der Knowledgebase. |
WEEK
| Syntax | WEEK(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt die Woche des angegebenen Datums <date> als Ganzzahl zurück. |
| Beispiel | WEEK(#1986-03-25#) = 13 |
| Hinweise | Siehe auch DAY, MONTH, QUARTER, YEAR und die ISO-Äquivalente |
YEAR
| Syntax | YEAR(date) |
| Ausgabe | Ganzzahl |
| Definition | Gibt das Jahr des angegebenen Datums <date> als Ganzzahl zurück. |
| Beispiel | YEAR(#1986-03-25#) = 1,986 |
| Hinweise | Siehe auch DAY, WEEK, MONTH, QUARTER und die ISO-Äquivalente |
AND
| Syntax | <expr1> AND <expr2> |
| Definition | Führt eine logische Verknüpfung von zwei Ausdrücken aus. (Wenn beide Seiten wahr sind, gibt der logische Test "true" zurück.) |
| Ausgabe | Boolesch (TRUE oder FALSE) |
| Beispiel | IF [Season] = "Spring" AND "[Season] = "Fall" "Wenn sowohl (Jahreszeit = Frühling) als auch (Jahreszeit = Herbst) gleichzeitig wahr sind, gib 'It's the apocalypse and footwear doesn't matter' (Das ist die Apokalypse und Schuhe spielen keine Rolle mehr) zurück.“ |
| Hinweise | Wird oft mit IF und IIF verwendet. Siehe auch NOT und OR. Wenn für beide Ausdrücke Wenn Sie eine Berechnung erstellen, in der das Ergebnis eines Hinweis: Der Operator |
CASE
| Syntax | CASE <expression>
|
| Ausgabe | Hängt vom Datentyp der <then>-Werte ab. |
| Definition | Bewertet den Ausdruck ( |
| Beispiel | "Betrachte das Feld 'Season' (Jahreszeit). Wenn der Wert 'Summer' (Sommer) lautet, gib 'Sandals' (Sandalen) zurück. Wenn der Wert 'Winter' lautet, gib 'Boots' (Stiefel) zurück. Wenn keine der Optionen in der Berechnung mit den Angaben im Feld 'Season' übereinstimmt, gib 'Sneakers' (Turnschuhe) zurück." |
| Hinweise | Verwendet mit WHEN, THEN, ELSE und END. Tipp: Oft können Sie eine Gruppe verwenden, um die gleichen Ergebnisse wie eine komplizierte CASE-Funktion zu erzielen, oder Sie können CASE verwenden, um wie im vorherigen Beispiel die native Gruppierungsfunktion zu ersetzen. Wir empfehlen zu prüfen, welche Variante für Ihr Szenario die bessere Leistung erzielt. |
ELSE
| Syntax | CASE <expression>
|
| Definition | Ein optionaler Teil eines IF- oder CASE-Ausdrucks, mit dem ein Standardwert festgelegt wird, der zurückgegeben werden soll, wenn keiner der getesteten Ausdrücke wahr ist. |
| Beispiel | IF [Season] = "Summer" THEN 'Sandals' CASE [Season] |
| Hinweise | Verwendet mit CASE, WHEN, IF, ELSEIF, THEN und END
|
ELSEIF
| Syntax | [ELSEIF <test2> THEN <then2>] |
| Definition | Ein optionaler Teil eines IF-Ausdrucks, mit dem Bedingungen zusätzlich zum ursprünglichen IF festgelegt werden. |
| Beispiel | IF [Season] = "Summer" THEN 'Sandals' |
| Hinweise | Verwendet mit IF, THEN, ELSE und END
Im Gegensatz zu |
END
| Definition | Wird zum Schließen eines IF- oder CASE-Ausdrucks verwendet. |
| Beispiel | IF [Season] = "Summer" THEN 'Sandals' "Wenn 'Season' (Jahreszeit) = 'Summer' (Sommer), dann gib 'Sandals' (Sandalen) zurück. Wenn nicht, schau dir den nächsten Ausdruck an. Wenn Jahreszeit = Winter, dann gib 'Boots' (Stiefel) zurück. Wenn keiner der Ausdrücke wahr ist, gib 'Sneakers' (Turnschuhe) zurück. CASE [Season] "Betrachte das Feld 'Season' (Jahreszeit). Wenn der Wert 'Summer' (Sommer) lautet, gib 'Sandals' (Sandalen) zurück. Wenn der Wert 'Winter' lautet, gib 'Boots' (Stiefel) zurück. Wenn keine der Optionen in der Berechnung mit den Angaben im Feld 'Season' übereinstimmt, gib 'Sneakers' (Turnschuhe) zurück." |
| Hinweise |
IF
| Syntax | IF <test1> THEN <then1> |
| Ausgabe | Hängt vom Datentyp der <then>-Werte ab. |
| Definition | Prüft eine Reihe von Ausdrücken und gibt den Wert |
| Beispiel | IF [Season] = "Summer" THEN 'Sandals' "Wenn 'Season' (Jahreszeit) = 'Summer' (Sommer), dann gib 'Sandals' (Sandalen) zurück. Wenn nicht, schau dir den nächsten Ausdruck an. Wenn Jahreszeit = Winter, dann gib 'Boots' (Stiefel) zurück. Wenn keiner der Ausdrücke wahr ist, gib 'Sneakers' (Turnschuhe) zurück. |
| Hinweise |
IFNULL
| Syntax | IFNULL(expr1, expr2) |
| Ausgabe | Hängt vom Datentyp der <expr>-Werte ab. |
| Definition | Gibt den Ausdruck |
| Beispiel | IFNULL([Assigned Room], "TBD") "Wenn das Feld 'Assigned Room' (Zugewiesenes Zimmer) nicht null ist, gib seinen Wert zurück. Wenn das Feld 'Assigned Room' null ist, gib stattdessen 'TBD' (Noch nicht festgelegt) zurück." |
| Hinweise | Vergleich mit ISNULL. Siehe auch ZN. |
IIF
| Syntax | IIF(<test>, <then>, <else>, [<unknown>]) |
| Ausgabe | Hängt vom Datentyp der Werte im Ausdruck ab. |
| Definition | Prüft, ob eine Bedingung erfüllt ist (<test>) und gibt <then> zurück, wenn der Test "true" ist, <else>, wenn der Test "false" ist, und einen optionalen Wert für <unknown>, wenn der Test null ist. Wenn die optionale Unbekannte nicht spezifiziert ist, gibt IIF null zurück. |
| Beispiel | IIF([Season] = 'Summer', 'Sandals', 'Other footwear') "Wenn 'Season' (Jahreszeit) = 'Summer' (Sommer), dann gib 'Sandals' (Sandalen) zurück. Wenn nicht, gib andere Schuhe zurück" IIF([Season] = 'Summer', 'Sandals', "Wenn 'Season' (Jahreszeit) = 'Summer' (Sommer), dann gib 'Sandals' (Sandalen) zurück. Wenn nicht, schau dir den nächsten Ausdruck an. Wenn Jahreszeit = Winter, dann gib 'Boots' (Stiefel) zurück. Wenn beides nicht zutrifft, gib 'Sneakers' (Turnschuhe) zurück." IIF('Season' = 'Summer', 'Sandals', "Wenn 'Season' (Jahreszeit) = 'Summer' (Sommer), dann gib 'Sandals' (Sandalen) zurück. Wenn nicht, schau dir den nächsten Ausdruck an. Wenn Jahreszeit = Winter, dann gib 'Boots' (Stiefel) zurück. Wenn keiner der Ausdrücke wahr ist, gib 'Sneakers' (Turnschuhe) zurück." |
| Hinweise |
Das heißt, in der folgenden Berechnung ist das Ergebnis rot und nicht orange, da der Ausdruck nicht weiter ausgewertet wird, sobald A=A als wahr ausgewertet wird:
|
IN
| Syntax | <expr1> IN <expr2> |
| Ausgabe | Boolesch (TRUE oder FALSE) |
| Definition | Gibt TRUE zurück, wenn ein beliebiger Wert in <expr1> mit einem beliebigen Wert in <expr2> übereinstimmt. |
| Beispiel | SUM([Cost]) IN (1000, 15, 200) "Ist der Wert des Kostenfelds 1000, 15 oder 200?" [Field] IN [Set] "Ist der Wert des Felds im Satz vorhanden?" |
| Hinweise | Die Werte in Siehe auch WHEN. |
ISDATE
| Syntax | ISDATE(string) |
| Ausgabe | Boolesch (TRUE oder FALSE) |
| Definition | Gibt "true" zurück, wenn <string> ein gültiges Datum ist. Der Eingabeausdruck muss ein Zeichenfolgenfeld (Textfeld) sein. |
| Beispiel | ISDATE("2018-09-22")"Ist die Zeichenfolge 2018-09-22 ein korrekt formatiertes Datum?" |
| Hinweise | Was als gültiges Datum gilt, hängt vom Gebietsschema(Link wird in neuem Fenster geöffnet) des Systems ab, das die Berechnung auswertet. Beispiel: In den USA:
Im Vereinigten Königreich:
|
ISNULL
| Syntax | ISNULL(expression) |
| Ausgabe | Boolesch (TRUE oder FALSE) |
| Definition | Gibt "true" zurück, wenn |
| Beispiel | ISNULL([Assigned Room]) "Ist das Feld 'Assigned Room" (Zugewiesenes Zimmer) null?" |
| Hinweise | Vergleichen Sie dieses mit IFNULL. Siehe auch ZN. |
MAX
| Syntax | MAX(expression) oder MAX(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Maximalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MAX(4,7) = 7 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
MIN
| Syntax | MIN(expression) oder MIN(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Minimalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MIN(4,7) = 4 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
NOT
| Syntax | NOT <expression> |
| Ausgabe | Boolesch (TRUE oder FALSE) |
| Definition | Führt eine logische Negation eines Ausdrucks durch. |
| Beispiel | IF NOT [Season] = "Summer" "Wenn die 'Season' (Jahreszeit) nicht gleich 'Summer' (Sommer) ist, dann gib 'Don't wear sandals' (Keine Sandalen tragen) zurück. Wenn nicht, gib 'Wear sandals' (Trag Sandalen) zurück." |
| Hinweise |
OR
| Syntax | <expr1> OR <expr2> |
| Ausgabe | Boolesch (TRUE oder FALSE) |
| Definition | Führt eine logische Disjunktion von zwei Ausdrücken aus. |
| Beispiel | IF [Season] = "Spring" OR [Season] = "Fall" "Wenn entweder (Jahreszeit = Spring) oder (Season = Fall) (Jahreszeit= Herbst) zutrifft, dann gib 'Sneakers' (Turnschuhe) zurück." |
| Hinweise | Wird oft mit IF und IIF verwendet. Siehe auch DATE und NOT. Wenn für einen der beiden Ausdrücke Wenn Sie eine Berechnung erstellen, in der in einem Arbeitsblatt das Ergebnis eines Hinweis: Der Operator |
THEN
| Syntax | IF <test1> THEN <then1>
|
| Definition | Ein erforderlicher Teil eines IF-, ELSEIF- oder CASE-Ausdrucks, mit dem definiert wird, welches Ergebnis zurückgegeben werden soll, wenn ein bestimmter Wert oder Test "true" ist. |
| Beispiel | IF [Season] = "Summer" THEN 'Sandals' "Wenn 'Season' (Jahreszeit) = 'Summer' (Sommer), dann gib 'Sandals' (Sandalen) zurück. Wenn nicht, schau dir den nächsten Ausdruck an. Wenn Jahreszeit = Winter, dann gib 'Boots' (Stiefel) zurück. Wenn keiner der Ausdrücke wahr ist, gib 'Sneakers' (Turnschuhe) zurück. CASE [Season] "Betrachte das Feld 'Season' (Jahreszeit). Wenn der Wert 'Summer' (Sommer) lautet, gib 'Sandals' (Sandalen) zurück. Wenn der Wert 'Winter' lautet, gib 'Boots' (Stiefel) zurück. Wenn keine der Optionen in der Berechnung mit den Angaben im Feld 'Season' übereinstimmt, gib 'Sneakers' (Turnschuhe) zurück." |
| Hinweise |
WHEN
| Syntax | CASE <expression>
|
| Definition | Ein erforderlicher Teil eines CASE-Ausdrucks. Sucht den ersten <value>, der mit <expression> übereinstimmt, und gibt den entsprechenden <then>-Wert zurück. |
| Beispiel | CASE [Season] "Betrachte das Feld 'Season' (Jahreszeit). Wenn der Wert 'Summer' (Sommer) lautet, gib 'Sandals' (Sandalen) zurück. Wenn der Wert 'Winter' lautet, gib 'Boots' (Stiefel) zurück. Wenn keine der Optionen in der Berechnung mit den Angaben im Feld 'Season' übereinstimmt, gib 'Sneakers' (Turnschuhe) zurück." |
| Hinweise | Verwendet mit CASE, THEN, ELSE und END.
CASE <expression> Die Werte, mit denen |
ZN
| Syntax | ZN(expression) |
| Ausgabe | Abhängig vom Datentyp von <expression> oder 0. |
| Definition | Gibt den <expression>-Wert zurück, sofern er nicht null ist; andernfalls wird 0 zurückgegeben. |
| Beispiel | ZN([Test Grade]) "Wenn 'Test Grade' (Testnote) nicht null ist, gib ihren Wert zurück. Wenn 'Test Grade' null ist, gib 0 zurück." |
| Hinweise |
Siehe auch ISNULL. |
ATTR
| Syntax | ATTR(expression) |
| Definition | Gibt den Wert des Ausdrucks zurück, wenn für alle Zeilen ein einziger Wert vorliegt. Andernfalls wird ein Sternchen zurückgegeben. Null-Werte werden ignoriert. |
AVG
| Syntax | AVG(expression) |
| Definition | Gibt den Mittelwert aller Werte im Ausdruck zurück. Null-Werte werden ignoriert. |
| Hinweise | AVG kann nur mit numerischen Feldern verwendet werden. |
COLLECT
| Syntax | COLLECT(spatial) |
| Definition | Eine Aggregationsberechnung, bei der Werte im Argumentfeld kombiniert werden. Null-Werte werden ignoriert. |
| Hinweise | COLLECT kann nur mit räumlichen Feldern verwendet werden. |
CORR
| Syntax | CORR(expression1, expression2) |
| Ausgabe | Zahl von -1 bis 1 |
| Definition | Gibt den Pearson-Korrelationskoeffizienten von zwei Ausdrücken zurück. |
| Beispiel | example |
| Hinweise | Bei der Kennzahl der Pearson-Korrelation handelt es sich um eine lineare Beziehung zwischen zwei Variablen. Der Ergebnisbereich liegt zwischen -1 und +1 (einschließlich), wobei 1 eine exakte positive lineare Beziehung bezeichnet, 0 bedeutet, dass keine lineare Beziehung zwischen der Varianz besteht, und -1 eine exakte negative Beziehung bedeutet. Das Quadrat eines CORR-Ergebnisses entspricht dem Bestimmtheitsmaß-Wert für ein lineares Trendlinienmodell. Weitere Informationen finden Sie unter Trendlinienmodell-Begriffe(Link wird in neuem Fenster geöffnet). Verwendung mit tabellenbereichsbezogenen LOD-Ausdrücken: Sie können CORR verwenden, um die Korrelation in einer disaggregierten Streuung mithilfe eines tabellenbereichsbezogenen Detailgenauigkeitsausdrucks(Link wird in neuem Fenster geöffnet) zu visualisieren. Beispiel: {CORR(Sales, Profit)}Die Korrelation wird mit einem Genauigkeitsausdruck über alle Reihen durchgeführt. Wenn Sie eine Formel wie z. B. |
| Datenbankseitige Einschränkungen |
Für andere Datenquellen können Sie entweder die Daten extrahieren oder |
COUNT
| Syntax | COUNT(expression) |
| Definition | Gibt die Anzahl der Elemente zurück. Null-Werte werden nicht gezählt. |
COUNTD
| Syntax | COUNTD(expression) |
| Definition | Gibt die Anzahl an eindeutigen Elementen in einer Gruppe zurück. Null-Werte werden nicht gezählt. |
COVAR
| Syntax | COVAR(expression1, expression2) |
| Definition | Gibt die Stichprobenkovarianz von zwei Ausdrücken zurück. |
| Hinweise | Die Kovarianz beziffert, auf welche Weise sich zwei Variablen gemeinsam ändern. Eine positive Kovarianz gibt an, dass die Variablen die Tendenz aufweisen, sich in die gleiche Richtung zu bewegen, und im Schnitt weisen höhere Werte einer Variablen die Tendenz auf, den höheren Werten der anderen Variablen zu entsprechen. Die Stichprobenkovarianz verwendet zum Normalisieren der Kovarianzberechnung die Anzahl n – 1 an Datenpunkten, die nicht null sind, anstelle von n, das von der Populationskovarianz verwendet wird (mit der Funktion Wenn Der Wert von |
| Datenbankseitige Einschränkungen |
Für andere Datenquellen können Sie entweder die Daten extrahieren oder |
COVARP
| Syntax | COVARP(expression 1, expression2) |
| Definition | Gibt die Populationskovarianz von zwei Ausdrücken zurück. |
| Hinweise | Die Kovarianz beziffert, auf welche Weise sich zwei Variablen gemeinsam ändern. Eine positive Kovarianz gibt an, dass die Variablen die Tendenz aufweisen, sich in die gleiche Richtung zu bewegen, und im Schnitt weisen höhere Werte einer Variablen die Tendenz auf, den höheren Werten der anderen Variablen zu entsprechen. Bei der Populationskovarianz handelt es sich um die Stichprobenkovarianz multipliziert mit (n–1)/n, wobei n für die Gesamtanzahl an Datenpunkten steht, die nicht null sind. Die Populationskovarianz ist die geeignete Wahl, wenn für alle gewünschten Elemente Daten vorhanden sind, im Gegensatz zu den Fällen, in denen nur eine zufällige Teilmenge an Elementen vorhanden ist. In solchen Fällen ist die Stichprobenkovarianz (mit der Funktion Wenn |
| Datenbankseitige Einschränkungen |
Für andere Datenquellen können Sie entweder die Daten extrahieren oder |
MAX
| Syntax | MAX(expression) oder MAX(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Maximalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MAX(4,7) = 7 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
MEDIAN
| Syntax | MEDIAN(expression) |
| Definition | Gibt den Median eines Ausdrucks über alle Datensätze hinweg zurück. Null-Werte werden ignoriert. |
| Hinweise | MEDIAN kann nur mit numerischen Feldern verwendet werden. |
| Datenbankseitige Einschränkungen |
Bei anderen Datenquellentypen können Sie Ihre Daten in eine Extraktdatei extrahieren, um diese Funktion zu nutzen. Informationen dazu finden Sie unter Extrahieren von Daten(Link wird in neuem Fenster geöffnet). |
MIN
| Syntax | MIN(expression) oder MIN(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Minimalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MIN(4,7) = 4 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
PERCENTILE
| Syntax | PERCENTILE(expression, number) |
| Definition | Gibt den Wert des angegebenen Ausdrucks als Perzentil zurück, das der angegebenen Zahl (<number>) entspricht. Die Zahl (<number>) muss eine numerische Konstante zwischen 0 und 1 (einschließlich) sein. |
| Beispiel | PERCENTILE([Score], 0.9) |
| Hinweise | |
| Datenbankseitige Einschränkungen | Diese Funktion ist für die folgenden Datenquellen verfügbar: Nicht-Legacy-Microsoft Excel- und Textdatei-Verbindungen, Extrakte und Datenquellen vom Typ "Nur-Extrakt" (z. B. Google Analytics, OData oder Salesforce), sowie Datenquellen der Versionen Sybase IQ 15.1 (und höher), Oracle 10 (und höher), Cloudera Hive und Hortonworks Hadoop Hive sowie EXASolution 4.2 (und höher). Bei anderen Datenquellentypen können Sie Ihre Daten in eine Extraktdatei extrahieren, um diese Funktion zu nutzen. Informationen dazu finden Sie unter Extrahieren von Daten(Link wird in neuem Fenster geöffnet). |
STDEV
| Syntax | STDEV(expression) |
| Definition | Gibt die statistische Standardabweichung aller Werte in einem Ausdruck basierend auf einer Stichprobe der Population zurück. |
STDEVP
| Syntax | STDEVP(expression) |
| Definition | Gibt die statistische Standardabweichung aller Werte in einem Ausdruck basierend auf einer verzerrten Population zurück. |
SUM
| Syntax | SUM(expression) |
| Definition | Gibt die Summe aller Werte im Ausdruck zurück. Null-Werte werden ignoriert. |
| Hinweise | SUM kann nur mit numerischen Feldern verwendet werden. |
VAR
| Syntax | VAR(expression) |
| Definition | Gibt die statistische Varianz aller Werte in einem Ausdruck basierend auf einer Stichprobe der Population zurück. |
VARP
| Syntax | VARP(expression) |
| Definition | Gibt die statistische Varianz aller Werte in einem Ausdruck basierend auf der Gesamtpopulation zurück. |
FULLNAME( )
| Syntax | FULLNAME( ) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt den vollständigen Namen des aktuellen Benutzers zurück. |
| Beispiel | FULLNAME( ) Gibt den vollständigen Namen des angemeldeten Benutzers zurück, z. B. "Hamlin Myrer". [Manager] = FULLNAME( ) Wenn der Manager namens Hamlin Myrer angemeldet ist, wird in diesem Beispiel nur dann der Wert "TRUE" zurückgegeben, wenn das Feld "Manager" in der Ansicht ebenfalls "Hamlin Myrer" enthält. |
| Hinweise | Diese Funktion prüft:
Benutzerfilter Ein berechnetes Feld, das als Filter verwendet wird, z. B. |
ISFULLNAME
| Syntax | ISFULLNAME("User Full Name") |
| Ausgabe | Boolesch |
| Definition | Gibt |
| Beispiel | ISFULLNAME("Hamlin Myrer") |
| Hinweise | Das Argument Diese Funktion prüft:
|
ISMEMBEROF
| Syntax | ISMEMBEROF("Group Name") |
| Ausgabe | Boolescher Wert oder Null |
| Definition | Gibt |
| Beispiel | ISMEMBEROF('Superstars')ISMEMBEROF('domain.lan\Sales') |
| Hinweise | Das Argument Wenn der Benutzer in Tableau Cloud oder Tableau Server angemeldet ist, wird die Gruppenmitgliedschaft durch Tableau-Gruppen bestimmt. Die Funktion gibt "TRUE" zurück, wenn die angegebene Zeichenfolge "Alle Benutzer" lautet. Die Funktion Wenn die Gruppenzugehörigkeit eines Benutzers geändert wird, wird die Änderung der Daten, die auf der Gruppenzugehörigkeit basieren, in einer Arbeitsmappe oder einer Ansicht mit einer neuen Sitzung wiedergegeben. In der vorhandenen Sitzung werden veraltete Daten angezeigt. |
ISUSERNAME
| Syntax | ISUSERNAME("username") |
| Ausgabe | Boolesch |
| Definition | Gibt TRUE zurück, wenn der Benutzername des aktuellen Benutzers dem angegebenen Benutzernamen entspricht. Andernfalls wird FALSE zurückgegeben. |
| Beispiel | ISUSERNAME("hmyrer") |
| Hinweise | Das Argument Diese Funktion prüft:
|
USERDOMAIN( )
| Syntax | USERDOMAIN( ) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die Domäne des aktuellen Benutzers zurück. |
| Hinweise | Diese Funktion prüft:
|
USERNAME( )
| Syntax | USERNAME( ) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt den Benutzernamen des aktuellen Benutzers zurück. |
| Beispiel | USERNAME( ) Gibt den Benutzernamen des angemeldeten Benutzers zurück, z. B. "hmyrer". [Manager] = USERNAME( ) Wenn der Manager "hmyrer" angemeldet ist, wird in diesem Beispiel nur dann der Wert "TRUE" zurückgegeben, wenn das Feld "Manager" in der Ansicht ebenfalls "hmyrer" enthält. |
| Hinweise | Diese Funktion prüft:
Benutzerfilter Ein berechnetes Feld, das als Filter verwendet wird, z. B. |
USERATTRIBUTE
Anmerkung: Nur für Einbettungs-Workflows in Tableau Cloud Weitere Informationen finden Sie unter Authentication and Embedded Views(Link wird in neuem Fenster geöffnet).
| Syntax | USERATTRIBUTE('attribute_name') |
| Ausgabe | Zeichenfolge oder Null |
| Definition | Wenn Gibt NULL zurück, wenn |
| Beispiel | Angenommen "Region" ist das Benutzerattribut, das im JWT enthalten ist und an Tableau übergeben wird (mithilfe der verbundenen Anwendung, die von Ihrem Site-Administrator bereits konfiguriert wurde). Als Autor der Arbeitsmappe können Sie Ihre Visualisierung so einrichten, dass Daten basierend auf einer bestimmten Region gefiltert werden. In diesem Filter können Sie auf die folgende Berechnung verweisen. [Region] = USERATTRIBUTE("Region")Wenn Benutzer 2 aus der Region "West" die eingebettete Visualisierung aufruft, zeigt Tableau nur die entsprechenden Daten für die Region "West" an. |
| Hinweise | Sie können die Funktion USERATTRIBUTEINCLUDES verwenden, wenn zu erwarten ist, dass <'attribute_name'> mehrere Werte zurückgibt. |
USERATTRIBUTEINCLUDES
Anmerkung: Nur für Einbettungs-Workflows in Tableau Cloud Weitere Informationen finden Sie unter Authentication and Embedded Views(Link wird in neuem Fenster geöffnet).
| Syntax | USERATTRIBUTEINCLUDES('attribute_name', 'expected_value') |
| Ausgabe | Boolesch |
| Definition | Gibt
Andernfalls wird |
| Beispiel | Angenommen "Region" ist das Benutzerattribut, das im JWT enthalten ist und an Tableau übergeben wird (mithilfe der verbundenen Anwendung, die von Ihrem Site-Administrator bereits konfiguriert wurde). Als Autor der Arbeitsmappe können Sie Ihre Visualisierung so einrichten, dass Daten basierend auf einer bestimmten Region gefiltert werden. In diesem Filter können Sie auf die folgende Berechnung verweisen. USERATTRIBUTEINCLUDES('Region', [Region])Wenn Benutzer 2 aus der Region "West" auf die eingebettete Visualisierung zugreift, prüft Tableau, ob das Benutzerattribut "Region" mit einem der Feldwerte "[Region]" übereinstimmt. Wenn ja, zeigt die Visualisierung die entsprechenden Daten an. Wenn Benutzer 3 aus der Region "Nord" auf dieselbe Visualisierung zugreift, werden keine Daten angezeigt, da es keine Übereinstimmung mit [Region]-Feldwerten gibt. |
FIRST( )
Gibt die Anzahl an Zeilen von der aktuellen Zeile bis zur ersten Zeile in der Partition zurück. In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Wenn FIRST() mit der Datumspartition berechnet wird, beträgt der Versatz von der ersten Zeile zur zweiten Zeile -1.
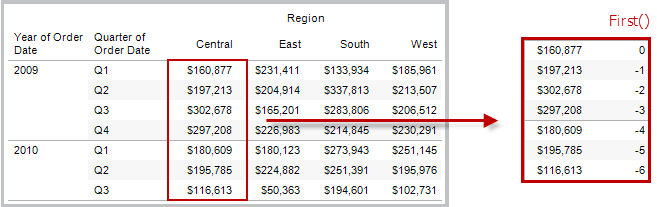
Beispiel
Bei einem aktuellen Zeilenindex von 3 gilt: FIRST()
= -2.
INDEX( )
Gibt den Index der aktuellen Zeile in der Partition zurück, ohne nach einem Wert zu sortieren. Der Index der ersten Zeile beginnt bei 1. Beispiel: In der Tabelle unten ist der Umsatz nach Quartal dargestellt. Wenn INDEX() mit der Datumspartition berechnet wird, lautet der Index der jeweiligen Zeile 1, 2, 3, 4... usw.
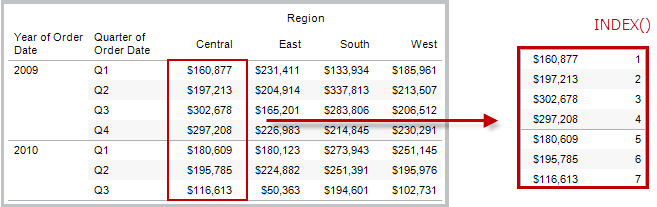
Beispiel
Für die dritte Zeile in der Partition gilt: INDEX() = 3.
LAST( )
Gibt die Anzahl an Zeilen von der aktuellen Zeile bis zur letzten Zeile in der Partition zurück. Beispiel: In der Tabelle unten ist der Umsatz nach Quartal dargestellt. Wenn LAST() mit der Datumspartition berechnet wird, beträgt der Versatz von der letzten Zeile zur zweiten Zeile 5.
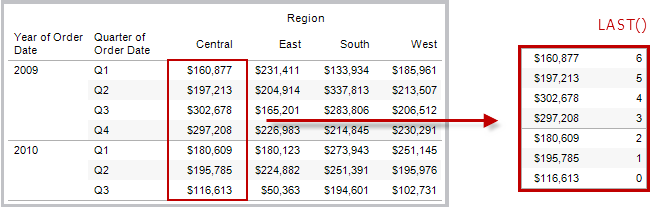
Beispiel
Bei einem aktuellen Zeilenindex von 3 von 7 gilt: LAST() = 4.
LOOKUP(expression, [offset])
Gibt den Wert des Ausdrucks in einer Zielzeile als relativen Versatz von der aktuellen Zeile zurück. Verwenden Sie FIRST() + n und LAST() - n als Teil der Versatzdefinition für ein Ziel relativ zur ersten/letzten Zeile in der Partition. Wenn der offset nicht angegeben wird, kann die Vergleichszeile im Feldmenü festgelegt werden. Diese Funktion gibt NULL zurück, wenn die Zielzeile nicht festgelegt werden kann.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Wenn LOOKUP (SUM(Sales), 2) mit der Datumspartition berechnet wird, wird in jeder Zeile der Umsatzwert aus dem zweitfolgenden Quartal angezeigt.
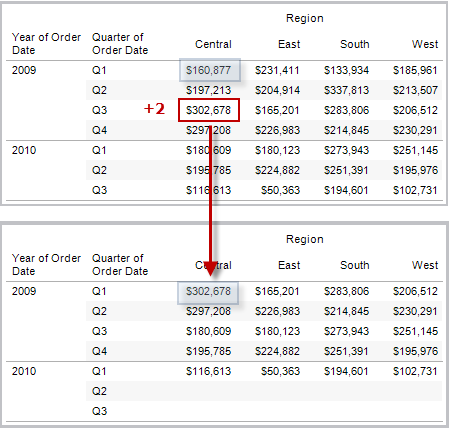
Beispiel
LOOKUP(SUM([Profit]),
FIRST()+2) berechnet in der dritten Zeile der Partition SUM(Profit).
MODEL_EXTENSION_BOOL (Modellname, Argumente, Ausdruck)
Gibt das boolesche Ergebnis eines Ausdrucks zurück, wie es von einem benannten Modell berechnet wurde, das in einem externen TabPy-Dienst bereitgestellt wird.
Der Modellname ist der Name des bereitgestellten Analysemodells, das Sie verwenden möchten.
Jedes Argument ist eine einzelne Zeichenfolge, die die Eingabewerte festlegt, die das bereitgestellte Modell akzeptiert, und wird durch das Analysemodell definiert.
Verwenden Sie Ausdrücke, um die Werte zu definieren, die von Tableau an das Analysemodell gesendet werden. Achten Sie darauf, Aggregationsfunktionen (SUM, AVG usw.) zu verwenden, um die Ergebnisse zu aggregieren.
Bei Verwendung der Funktion müssen die Datentypen und die Reihenfolge der Ausdrücke mit denen der Eingabeargumente übereinstimmen.
Beispiel
MODEL_EXTENSION_BOOL ("isProfitable","inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_INT (Modellname, Argumente, Ausdruck)
Gibt ein ganzzahliges Ergebnis eines Ausdrucks zurück, wie von einem benannten Modell berechnet, das in einem externen TabPy-Dienst bereitgestellt wird.
Der Modellname ist der Name des bereitgestellten Analysemodells, das Sie verwenden möchten.
Jedes Argument ist eine einzelne Zeichenfolge, die die Eingabewerte festlegt, die das bereitgestellte Modell akzeptiert, und wird durch das Analysemodell definiert.
Verwenden Sie Ausdrücke, um die Werte zu definieren, die von Tableau an das Analysemodell gesendet werden. Achten Sie darauf, Aggregationsfunktionen (SUM, AVG usw.) zu verwenden, um die Ergebnisse zu aggregieren.
Bei Verwendung der Funktion müssen die Datentypen und die Reihenfolge der Ausdrücke mit denen der Eingabeargumente übereinstimmen.
Beispiel
MODEL_EXTENSION_INT ("getPopulation", "inputCity", "inputState", MAX([City]), MAX ([State]))
MODEL_EXTENSION_REAL (Modellname, Argumente, Ausdruck)
Gibt ein echtes Ergebnis eines Ausdrucks zurück, wie von einem benannten Modell berechnet, das in einem externen TabPy-Dienst bereitgestellt wird.
Der Modellname ist der Name des bereitgestellten Analysemodells, das Sie verwenden möchten.
Jedes Argument ist eine einzelne Zeichenfolge, die die Eingabewerte festlegt, die das bereitgestellte Modell akzeptiert, und wird durch das Analysemodell definiert.
Verwenden Sie Ausdrücke, um die Werte zu definieren, die von Tableau an das Analysemodell gesendet werden. Achten Sie darauf, Aggregationsfunktionen (SUM, AVG usw.) zu verwenden, um die Ergebnisse zu aggregieren.
Bei Verwendung der Funktion müssen die Datentypen und die Reihenfolge der Ausdrücke mit denen der Eingabeargumente übereinstimmen.
Beispiel
MODEL_EXTENSION_REAL ("profitRatio", "inputSales", "inputCosts", SUM([Sales]), SUM([Costs]))
MODEL_EXTENSION_STRING (Modellname, Argumente, Ausdruck)
Gibt das Zeichenfolgenergebnis eines Ausdrucks zurück, wie es von einem benannten Modell berechnet wurde, das in einem externen TabPy-Dienst bereitgestellt wird.
Der Modellname ist der Name des bereitgestellten Analysemodells, das Sie verwenden möchten.
Jedes Argument ist eine einzelne Zeichenfolge, die die Eingabewerte festlegt, die das bereitgestellte Modell akzeptiert, und wird durch das Analysemodell definiert.
Verwenden Sie Ausdrücke, um die Werte zu definieren, die von Tableau an das Analysemodell gesendet werden. Achten Sie darauf, Aggregationsfunktionen (SUM, AVG usw.) zu verwenden, um die Ergebnisse zu aggregieren.
Bei Verwendung der Funktion müssen die Datentypen und die Reihenfolge der Ausdrücke mit denen der Eingabeargumente übereinstimmen.
Beispiel
MODEL_EXTENSION_STR ("mostPopulatedCity", "inputCountry", "inputYear", MAX ([Country]), MAX([Year]))
MODEL_PERCENTILE(target_expression, predictor_expression(s))
Gibt die Wahrscheinlichkeit (zwischen 0 und 1) zurück, dass der erwartete Wert kleiner oder gleich der beobachteten Markierung ist, die durch den Zielausdruck und andere Prädiktoren definiert wird. Dies ist die A-Posteriori-Verteilungsfunktion oder kumulative Verteilungsfunktion (CDF, Cumulative Distribution Function).
Diese Funktion ist die Umkehrung von MODEL_QUANTILE. Informationen zu prädiktiven Modellierungsfunktionen finden Sie unter Funktionsweise der Vorhersagemodellierungsfunktionen in Tableau.
Beispiel
Die folgende Formel gibt das Quantil der Markierung für die Summe der Umsätze zurück, bereinigt um die Anzahl der Aufträge.
MODEL_PERCENTILE(SUM([Sales]), COUNT([Orders]))
MODEL_QUANTILE(quantile, target_expression, predictor_expression(s))
Gibt einen numerischen Zielwert innerhalb des wahrscheinlichen Bereichs zurück, der durch den Zielausdruck und andere Prädiktoren bei einem angegebenen Quantil definiert wird. Dies ist das A-Posteriori-Quantil.
Diese Funktion ist die Umkehrung von MODEL_PERCENTILE. Informationen zu prädiktiven Modellierungsfunktionen finden Sie unter Funktionsweise der Vorhersagemodellierungsfunktionen in Tableau.
Beispiel
Die folgende Formel gibt den Median der vorhergesagten Umsatzsumme (0,5) zurück, bereinigt um die Anzahl der Aufträge.
MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders]))
PREVIOUS_VALUE(expression)
Gibt den Wert dieser Berechnung in der vorherigen Zeile zurück. Gibt den entsprechenden Ausdruck zurück, wenn die aktuelle Zeile die erste Zeile der Partition ist.
Beispiel
SUM([Profit]) * PREVIOUS_VALUE(1) errechnet das laufende Produkt von SUM(Profit).
RANK(expression, ['asc' | 'desc'])
Gibt den standardmäßigen Konkurrenzrang für die aktuelle Zeile in der Partition zurück. Identischen Werten wird ein identischer Rang zugewiesen. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist absteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (4, 2, 2, 1) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
Beispiel
Die folgende Abbildung zeigt die Wirkung der verschiedenen Rangfunktionen (RANK, RANK_DENSE, RANK_MODIFIED, RANK_PERCENTILE und RANK_UNIQUE) auf einen Wertesatz. Der Datensatz umfasst Informationen zu 14 Studenten (StudentA bis StudentN). Die Spalte Alter zeigt das aktuelle Alter der Studenten an (alle Studenten sind zwischen 17 und 20 Jahre alt). Die restlichen Spalten zeigen die Auswirkung von jeder Rang-Funktion auf den Wertesatz für das Alter. Dabei wird vorausgesetzt, dass die Standard-Sortierreihenfolge (auf- oder absteigend) für die Funktion verwendet wird.
![]()
RANK_DENSE(expression, ['asc' | 'desc'])
Gibt den dichten Rang für die aktuelle Zeile in der Partition zurück. Identischen Werten wird der gleiche Rang zugewiesen. In die Zahlenreihenfolge werden keine Leerstellen eingefügt. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist absteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (3, 2, 2, 1) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
RANK_MODIFIED(expression, ['asc' | 'desc'])
Gibt den geänderten Konkurrenzrang für die aktuelle Zeile in der Partition zurück. Identischen Werten wird ein identischer Rang zugewiesen. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist absteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (4, 3, 3, 1) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
RANK_PERCENTILE(expression, ['asc' | 'desc'])
Gibt den Perzentilrang für die aktuelle Zeile in der Partition zurück. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist aufsteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (0,00, 0,67, 0,67, 1,00) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
RANK_UNIQUE(expression, ['asc' | 'desc'])
Gibt den eindeutigen Rang für die aktuelle Zeile in der Partition zurück. Identischen Werten werden unterschiedlich Ränge zugewiesen. Verwenden Sie das optionale Argument 'asc' | 'desc', um die aufsteigende oder absteigende Reihenfolge anzugeben. Die Standardeinstellung ist absteigend.
Gemäß dieser Funktion würde der Wertesatz (6, 9, 9, 14) die Rangfolge (4, 2, 3, 1) aufweisen.
Nullen werden in Rangfunktionen ignoriert. Sie werden nicht nummeriert und nicht auf die Gesamtanzahl Datensätze bei Perzentil-Rangberechnungen angerechnet.
Informationen zu verschiedenen Rangoptionen finden Sie unter Berechnung "Rang".
RUNNING_AVG(expression)
Gibt den laufenden Durchschnitt des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Wenn RUNNING_AVG(SUM([Sales]) mit der Datumspartition berechnet wird, ist das Ergebnis ein laufender Durchschnitt der Umsatzwerte für jedes Quartal.
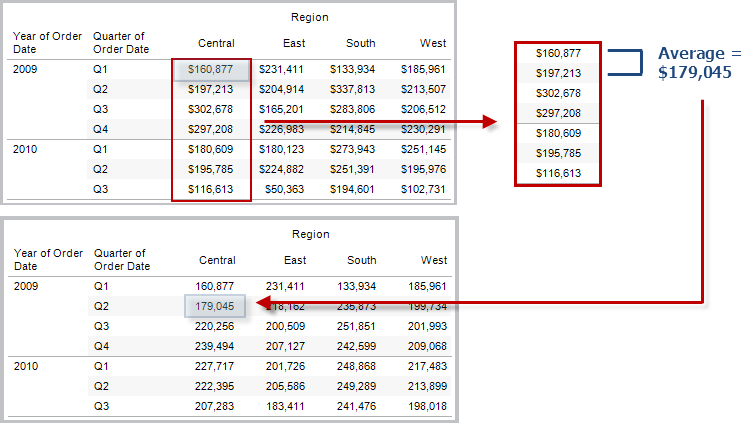
Beispiel
RUNNING_AVG(SUM([Profit])) errechnet das laufende Produkt von SUM(Profit).
RUNNING_COUNT(expression)
Gibt die laufende Anzahl des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.
Beispiel
RUNNING_COUNT(SUM([Profit])) errechnet die laufende Anzahl von SUM(Profit).
RUNNING_MAX(expression)
Gibt das laufende Maximum des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.
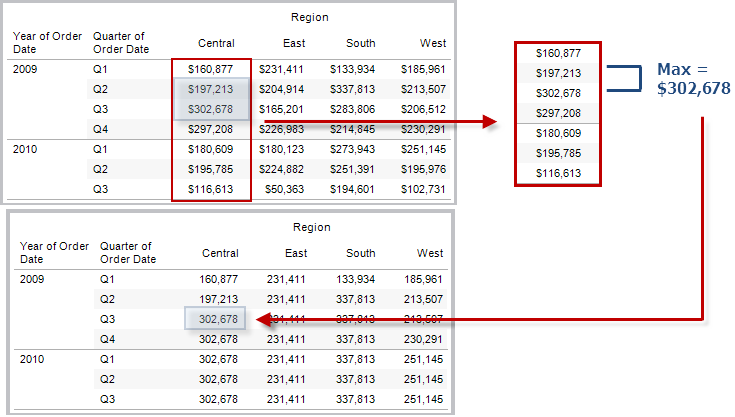
Beispiel
RUNNING_MAX(SUM([Profit])) errechnet das laufende Maximum von SUM(Profit).
RUNNING_MIN(expression)
Gibt das laufende Minimum des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.
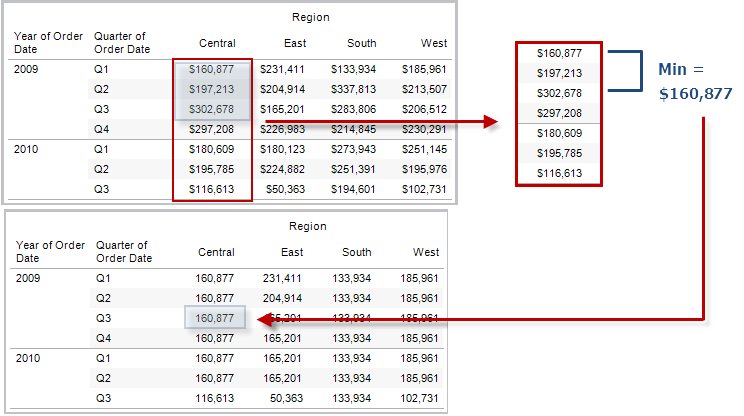
Beispiel
RUNNING_MIN(SUM([Profit])) errechnet das laufende Minimum von SUM(Profit).
RUNNING_SUM(expression)
Gibt die laufende Summe des Ausdrucks zurück, von der ersten Zeile der Partition bis zur aktuellen Zeile.
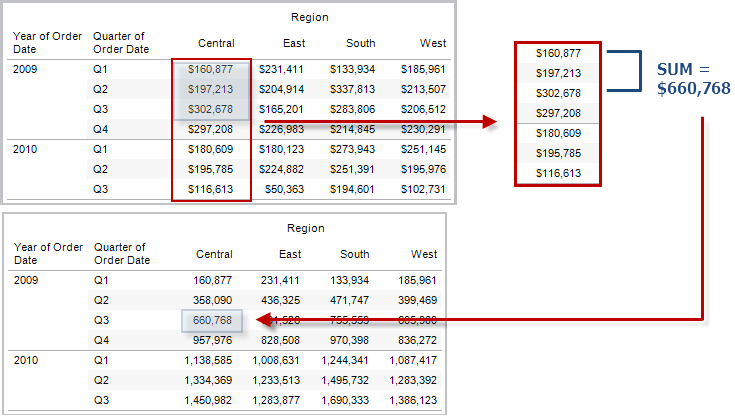
Beispiel
RUNNING_SUM(SUM([Profit])) errechnet die laufende Summe von SUM(Profit).
SIZE()
Gibt die Anzahl an Zeilen in der Partition zurück. In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Innerhalb der Datumspartition gibt es sieben Zeilen. Somit ist Size() der Datumspartition gleich 7.
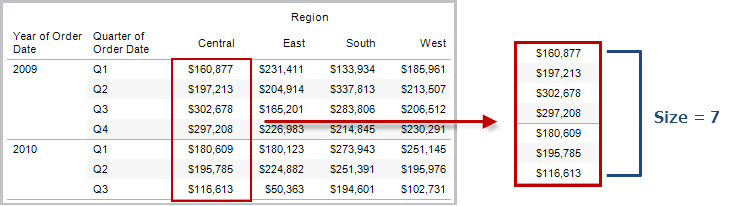
Beispiel
SIZE() = 5, wenn die aktuelle Partition fünf Zeilen enthält.
SCRIPT_BOOL
Gibt ein Boolesches Ergebnis für den angegebenen Ausdruck zurück. Der Ausdruck wird direkt an eine ausgeführte externe Dienstinstanz übergeben.
In R-Ausdrücken verweisen Sie mit .argn (mit vorangestelltem Punkt) auf Parameter (.arg1, .arg2, usw.).
In Python-Ausdrücken verwenden Sie dagegen _argn (mit vorangestelltem Unterstrich).
Beispiele
In diesem R-Beispiel steht .arg1 für SUM([Profit]):
SCRIPT_BOOL("is.finite(.arg1)", SUM([Profit]))
Das nächste Beispiel gibt "true" für Store-IDs im Bundesstaat Washington zurück, andernfalls "false". Bei diesem Beispiel kann es sich um die Definition für ein berechnetes Feld mit dem Titel IsStoreInWA handeln.
SCRIPT_BOOL('grepl(".*_WA", .arg1, perl=TRUE)',ATTR([Store ID]))
Ein Befehl für Python würde dieses Formular verwenden:
SCRIPT_BOOL("return map(lambda x : x > 0, _arg1)", SUM([Profit]))
SCRIPT_INT
Gibt eine Ganzzahl für den angegebenen Ausdruck zurück. Der Ausdruck wird direkt an eine ausgeführte externe Dienstinstanz übergeben.
In R-Ausdrücken verweisen Sie mit .argn (mit vorangestelltem Punkt) auf Parameter (.arg1, .arg2, usw.).
In Python-Ausdrücken verwenden Sie dagegen _argn (mit vorangestelltem Unterstrich).
Beispiele
In diesem R-Beispiel steht .arg1 für SUM([Profit]):
SCRIPT_INT("is.finite(.arg1)", SUM([Profit]))
Im nächsten Beispiel wird k-means-Clustering zur Erstellung von drei Clustern verwendet:
SCRIPT_INT('result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);result$cluster;', SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]))
Ein Befehl für Python würde dieses Formular verwenden:
SCRIPT_INT("return map(lambda x : int(x * 5), _arg1)", SUM([Profit]))
SCRIPT_REAL
Gibt eine reelle Zahl für den angegebenen Ausdruck zurück. Der Ausdruck wird direkt an eine ausgeführte externe Dienstinstanz übergeben. In
In R-Ausdrücken verweisen Sie mit .argn (mit vorangestelltem Punkt) auf Bezugsparameter (.arg1, .arg2 usw.).
In Python-Ausdrücken verwenden Sie dagegen _argn (mit vorangestelltem Unterstrich).
Beispiele
In diesem R-Beispiel steht .arg1 für SUM([Profit]):
SCRIPT_REAL("is.finite(.arg1)", SUM([Profit]))
Das nächste Beispiel konvertiert Temperaturwerte von Celsius in Fahrenheit.
SCRIPT_REAL('library(udunits2);ud.convert(.arg1, "celsius", "degree_fahrenheit")',AVG([Temperature]))
Ein Befehl für Python würde dieses Formular verwenden:
SCRIPT_REAL("return map(lambda x : x * 0.5, _arg1)", SUM([Profit]))
SCRIPT_STR
Gibt eine Zeichenfolge für den angegebenen Ausdruck zurück. Der Ausdruck wird direkt an eine ausgeführte externe Dienstinstanz übergeben.
In R-Ausdrücken verweisen Sie mit .argn (mit vorangestelltem Punkt) auf Parameter (.arg1, .arg2, usw.).
In Python-Ausdrücken verwenden Sie dagegen _argn (mit vorangestelltem Unterstrich).
Beispiele
In diesem R-Beispiel steht .arg1 für SUM([Profit]):
SCRIPT_STR("is.finite(.arg1)", SUM([Profit]))
Das nächste Beispiel extrahiert die Abkürzung für einen Bundesstaat aus einer komplexeren Zeichenfolge (in der Originalform 13XSL_CA, A13_WA):
SCRIPT_STR('gsub(".*_", "", .arg1)',ATTR([Store ID]))
Ein Befehl für Python würde dieses Formular verwenden:
SCRIPT_STR("return map(lambda x : x[:2], _arg1)", ATTR([Region]))
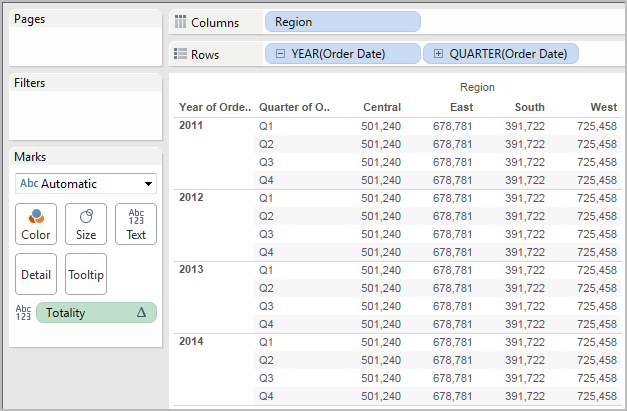
TOTAL(expression)
Gibt den Gesamtwert für den angegebenen Ausdruck in einer Tabellenberechnungspartition zurück.
Beispiel
Angenommen, Sie starten mit dieser Ansicht:

Sie öffnen den Berechnungs-Editor und erstellen ein neues Feld mit dem Namen Gesamtwert:
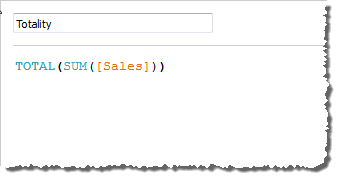
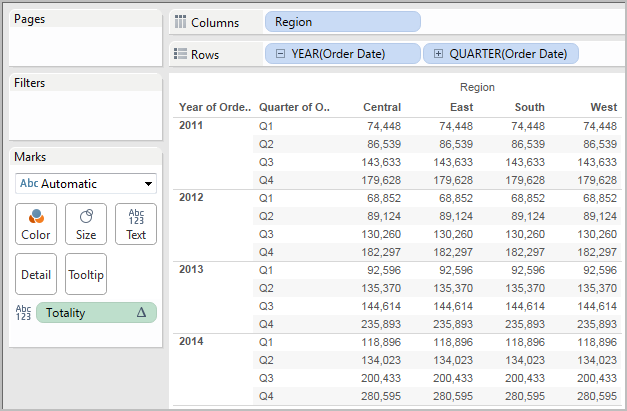
Dann ziehen Sie das Feld Gesamtwert auf "Text", um SUMME(Umsatz) zu ersetzen. Ihre Ansicht ändert sich insoweit, dass die Werte basierend auf dem Standardwert für Berechnung per summiert werden:
Dabei stellt sich die Frage: "Was ist der Standardwert für Berechnung per?" Wenn Sie mit der rechten Maustaste (Strg-Mausklick auf einem Mac) im Bereich "Daten" auf Gesamtwert klicken, und die Option Bearbeiten auswählen, stehen nun weitere Informationen zur Verfügung:
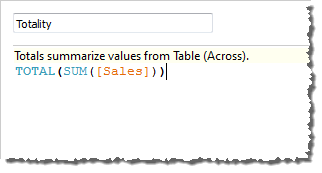
Der Standardwert für Berechnung per ist Tabelle (quer). Das Ergebnis ist, dass das Feld Gesamtwert die Werte aus jeder Zeile in Ihrer Tabelle summiert. Daher ist der Wert, den Sie in jeder Zeile sehen können, die Summe der Werte aus der Originalversion der Tabelle.
Die Werte in der Zeile "2011/Q1" in der Originaldatei lauten $8601, $6579, $44262 und $15006. Die Werte in der Tabelle, nachdem SUMME(Umsatz) durch Gesamtwert ersetzt wurde, lauten alle $74,448. Dies ist die Summe der vier Originalwerte.
Beachten Sie das Dreieck neben "Gesamtwert", nachdem Sie das Feld auf "Text" gezogen haben:
Dieses gibt an, dass es sich bei dem Feld um eine Tabellenberechnung handelt. Sie können mit der rechten Maustaste auf das Feld klicken und die Option Tabellenberechnung auswählen, um Ihre Funktion mit einem anderen Wert für Berechnung per zu verknüpfen. Sie könnten beispielsweise Tabelle (abwärts) auswählen. In diesem Fall würde Ihre Tabelle wie folgt aussehen:
WINDOW_AVG(expression, [start, end])
Gibt den Mittelwert des Ausdrucks im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Ein innerhalb der Datumspartition berechneter Fenster-Mittelwert gibt den durchschnittlichen Umsatz über alle Datumsangaben hinweg zurück.
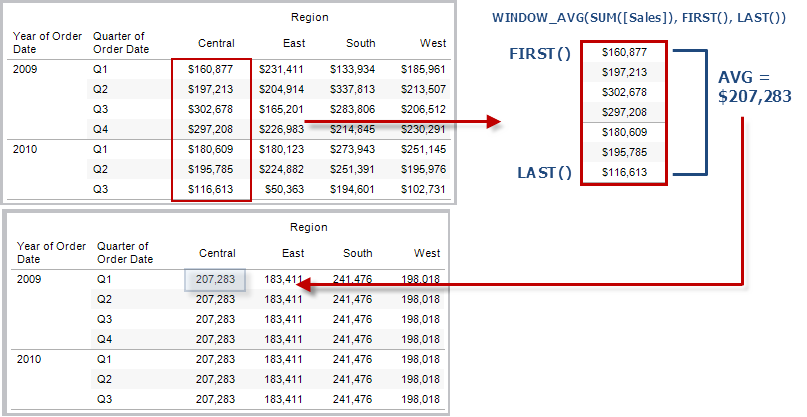
Beispiel
WINDOW_AVG(SUM([Profit]), FIRST()+1, 0) berechnet den Durchschnitt für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_CORR(expression1, expression2, [Start, Ende])
Gibt den Pearson-Korrelationskoeffizienten von zwei Ausdrücken innerhalb des Fensters zurück. Das Fenster ist jeweils als Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn der Start und das Ende ausgelassen werden, wird die gesamte Partition verwendet.
Bei der Kennzahl der Pearson-Korrelation handelt es sich um eine lineare Beziehung zwischen zwei Variablen. Der Ergebnisbereich liegt zwischen -1 und +1 einschließlich, wobei 1 eine exakte positive lineare Beziehung bezeichnet, d. h. eine positive Änderung einer Variablen impliziert eine positive Änderung des zugehörigen Wertes der anderen Variablen. 0 bedeutet, dass keine lineare Beziehung zwischen der Varianz besteht, und -1 bedeutet eine exakte negative Beziehung.
Es gibt eine gleichwertige Aggregationsfunktion: CORR. Informationen finden Sie unter Tableau-Funktionen (alphabetisch)(Link wird in neuem Fenster geöffnet).
Beispiel
Die folgende Formel gibt die Pearson-Korrelation von SUM(Gewinn) und SUM(Umsatz) von den fünf vorausgehenden bis zur aktuellen Zeile zurück.
WINDOW_CORR(SUM[Profit]), SUM([Sales]), -5, 0)
WINDOW_COUNT(expression, [start, end])
Gibt die Anzahl für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_COUNT(SUM([Profit]), FIRST()+1, 0) berechnet die Anzahl für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_COVAR(expression1, expression2, [start, end])
Gibt die Stichprobenkovarianz von zwei Ausdrücken innerhalb des Fensters zurück. Das Fenster ist jeweils als Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn die Start- und Endargumente ausgelassen werden, wird das Fenster zur gesamten Partition.
Die Stichprobenkovarianz verwendet die Anzahl an n – 1 Datenpunkten, die nicht null sind, zum Normalisieren der Kovarianzberechnung, anstelle von n, das von der Populationskovarianz verwendet wird (mit der Funktion "WINDOW_COVARP"). Die Stichprobenkovarianz ist dann die richtige Wahl, wenn es sich bei den Daten um eine Zufallsstichprobe handelt, die zum Schätzen der Kovarianz für eine größere Population verwendet wird.
Es gibt eine gleichwertige Aggregationsfunktion: COVAR. Informationen finden Sie unter Tableau-Funktionen (alphabetisch)(Link wird in neuem Fenster geöffnet).
Beispiel
Die folgende Formel gibt die Stichprobenkovarianz von SUM(Gewinn) und SUM(Umsatz) von den beiden vorausgehenden bis zur aktuellen Zeile zurück.
WINDOW_COVAR(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_COVARP(expression1, expression2, [start, end])
Gibt die Populationskovarianz von zwei Ausdrücken innerhalb des Fensters zurück. Das Fenster ist jeweils als Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn der Start und das Ende ausgelassen werden, wird die gesamte Partition verwendet.
Bei der Populationskovarianz handelt es sich um die Stichprobenkovarianz multipliziert mit (n–1)/n, wobei n für die Gesamtanzahl an Datenpunkten steht, die nicht null sind. Die Populationskovarianz ist die geeignete Wahl, wenn für alle gewünschten Elemente Daten vorhanden sind, im Gegensatz zu den Fällen, in denen nur eine zufällige Teilmenge an Elementen vorhanden ist. In solchen Fällen ist die Stichprobenkovarianz (mit der Funktion "WINDOW_COVAR") die geeignete Wahl.
Es gibt eine gleichwertige Aggregationsfunktion: COVARP. Tableau-Funktionen (alphabetisch)(Link wird in neuem Fenster geöffnet).
Beispiel
Die folgende Formel gibt die Populationskovarianz von SUM(Gewinn) und SUM(Umsatz) von den beiden vorausgehenden bis zur aktuellen Zeile zurück.
WINDOW_COVARP(SUM([Profit]), SUM([Sales]), -2, 0)
WINDOW_MEDIAN(expression, [start, end])
Gibt den Median für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel: In der Ansicht unten ist der Gewinn nach Quartal dargestellt. Ein innerhalb der Datumspartition berechneter Fenster-Median gibt den Medianwert des Gewinns über alle Datumsangaben hinweg zurück.
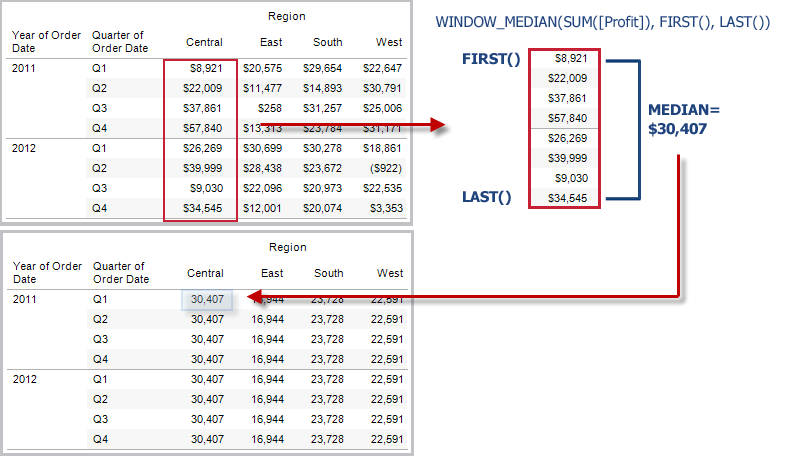
Beispiel
WINDOW_MEDIAN(SUM([Profit]), FIRST()+1, 0) berechnet den kleinsten Wert für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_MAX(expression, [start, end])
Gibt das Maximum für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Ein innerhalb der Datumspartition berechneter Fenster-Maximalwert gibt den höchsten Umsatz über alle Datumsangaben hinweg zurück.

Beispiel
WINDOW_MAX(SUM([Profit]), FIRST()+1, 0) berechnet den größten Wert für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_MIN(expression, [start, end])
Gibt das Minimum für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Ein innerhalb der Datumspartition berechneter Fenster-Minimalwert gibt den geringsten Umsatz über alle Datumsangaben hinweg zurück.
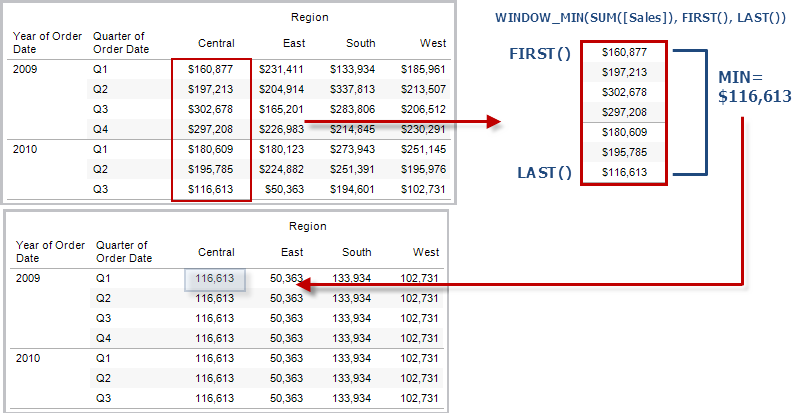
Beispiel
WINDOW_MIN(SUM([Profit]), FIRST()+1, 0) berechnet den kleinsten Wert für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_PERCENTILE(expression, number, [start, end])
Gibt den Wert zurück, der dem angegebenen Perzentil innerhalb des Fensters entspricht. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_PERCENTILE(SUM([Profit]), 0.75, -2, 0) gibt das 75. Perzentil für SUM(Profit) von den beiden vorangegangenen Zeilen bis zur aktuellen Zeile zurück.
WINDOW_STDEV(expression, [start, end])
Gibt die Beispielstandardabweichung für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_STDEV(SUM([Profit]), FIRST()+1, 0) berechnet die Standardabweichung für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_STDEVP(expression, [start, end])
Gibt die unausgewogene Standardabweichung für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_STDEVP(SUM([Profit]), FIRST()+1, 0) berechnet die Standardabweichung für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_SUM(expression, [start, end])
Gibt die Summe des Ausdrucks innerhalb des Fensters zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
In der Ansicht unten ist der Umsatz nach Quartal dargestellt. Eine innerhalb der Datumspartition berechnete Fenster-Summe gibt die Summe der Umsätze über alle Quartale hinweg zurück.
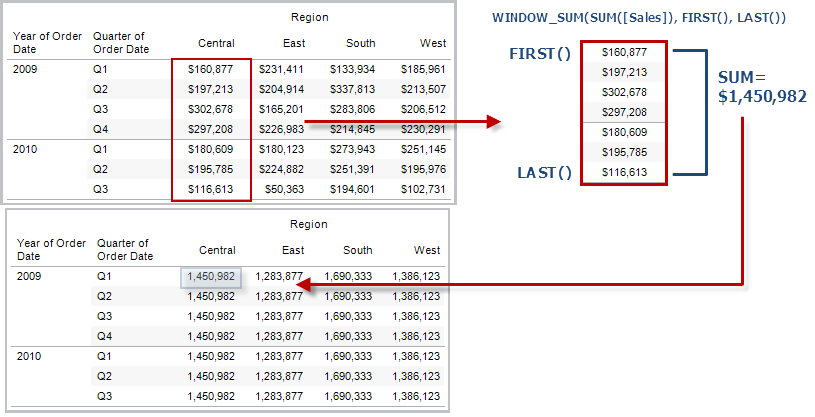
Beispiel
WINDOW_SUM(SUM([Profit]), FIRST()+1, 0) berechnet die Summe für SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_VAR(expression, [start, end])
Gibt die Beispielvarianz für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_VAR((SUM([Profit])), FIRST()+1, 0) errechnet die Varianz von SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
WINDOW_VARP(expression, [start, end])
Gibt die unausgewogene Varianz für den Ausdruck im Fenster zurück. Das Fenster ist jeweils mittels Versatz von der aktuellen Zeile definiert. Verwenden Sie FIRST()+n und LAST()-n für den Versatz von der ersten oder letzten Zeile in der Partition. Wenn kein Start- und Endpunkt angegeben wird, wird die gesamte Partition verwendet.
Beispiel
WINDOW_VARP(SUM([Profit]), FIRST()+1, 0) errechnet die Varianz von SUM(Profit) von der zweiten Zeile bis zur aktuellen Zeile.
Diese RAWSQL-Pass-Through-Funktionen können verwendet werden, um SQL-Ausdrücke direkt in die Datenbank weiterzuleiten, ohne diese durch Tableau interpretieren zu lassen. Wenn Sie über benutzerdefinierte Datenbankfunktionen verfügen, die Tableau nicht bekannt sind, können Sie diese benutzerdefinierten Funktionen über die Pass-Through-Funktionen aufrufen.
Normalerweise kann Ihre Datenbank die Feldnamen, die in Tableau angezeigt werden, nicht verarbeiten. Da Tableau die SQL-Ausdrücke nicht interpretiert, die Sie über die Pass-Through-Funktionen einschließen, kann eine Verwendung der Feldnamen von Tableau in Ihrem Ausdruck Fehler hervorrufen. Sie können eine Ersatzsyntax verwenden, um den korrekten Feldnamen oder Ausdruck für eine Tableau-Berechnung in die SQL Pass-Through-Funktion einzufügen. Beispiel: Sie verfügen über eine Funktion, die den Median für einen Satz an Werten berechnet. In diesem Fall können Sie die Funktion in der Tableau-Spalte [Sales] wie folgt aufrufen:
RAWSQLAGG_REAL(“MEDIAN(%1)”, [Sales])
Da Tableau den Ausdruck nicht interpretiert, müssen Sie die Aggregation definieren. Sie können die nachfolgend beschriebenen RAWSQLAGG-Funktionen für aggregierte Ausdrücke verwenden.
RAWSQL-Pass-Through-Funktionen funktionieren möglicherweise nicht mit Extrakten oder veröffentlichten Datenquellen, wenn sie Beziehungen enthalten.
RAWSQL-Funktionen
In Tableau sind die nachfolgenden RAWSQL-Funktionen verfügbar.
RAWSQL_BOOL(“sql_expr”, [arg1], …[argN])
Gibt für einen angegebenen SQL-Ausdruck ein boolesches Ergebnis zurück. Der SQL-Ausdruck wird direkt an die zugrunde liegende Datenbank übergeben. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte.
Beispiel
Im Beispiel steht %1 für [Sales] und %2 für [Profit].
RAWSQL_BOOL(“IIF( %1 > %2, True, False)”, [Sales], [Profit])
RAWSQL_DATE("sql_expr”, [arg1], …[argN])
Gibt für einen angegebenen SQL-Ausdruck ein Datumsergebnis zurück. Der SQL-Ausdruck wird direkt an die zugrunde liegende Datenbank übergeben. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte.
Beispiel
In diesem Beispiel steht %1 für [Order Date].
RAWSQL_DATE(“%1”, [Order
Date])
RAWSQL_DATETIME("sql_expr”, [arg1], …[argN])
Gibt für einen angegebenen SQL-Ausdruck Datum und Uhrzeit zurück. Der SQL-Ausdruck wird direkt an die zugrunde liegende Datenbank übergeben. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Delivery Date].
Beispiel
RAWSQL_DATETIME(“MIN(%1)”, [Delivery Date])
RAWSQL_INT("sql_expr”, [arg1], …[argN])
Gibt für einen angegebenen SQL-Ausdruck eine Ganzzahl zurück. Der SQL-Ausdruck wird direkt an die zugrunde liegende Datenbank übergeben. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Sales].
Beispiel
RAWSQL_INT(“500
+ %1”, [Sales])
RAWSQL_REAL("sql_expr”, [arg1], …[argN])
Gibt ein numerisches Ergebnis für einen angegebenen SQL-Ausdruck zurück, der direkt an die zugrunde liegende Datenquelle übergeben wird. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Sales].
Beispiel
RAWSQL_REAL(“-123.98 * %1”, [Sales])
RAWSQL_SPATIAL
Gibt ein räumliches Feld für einen angegebenen SQL-Ausdruck zurück, das direkt an die zugrunde liegende Datenquelle übergeben wird. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte.
Beispiel
In diesem Beispiel steht %1 für [Geometry].
RAWSQL_SPATIAL("%1", [Geometry])
RAWSQL_STR("sql_expr”, [arg1], …[argN])
Gibt eine Zeichenfolge für einen angegebenen SQL-Ausdruck zurück, der direkt an die zugrunde liegende Datenquelle übergeben wird. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Customer Name].
Beispiel
RAWSQL_STR(“%1”, [Customer Name])
RAWSQLAGG_BOOL("sql_expr”, [arg1], …[argN])
Gibt für einen angegebenen aggregierten SQL-Ausdruck ein boolesches Ergebnis zurück. Der SQL-Ausdruck wird direkt an die zugrunde liegende Datenbank übergeben. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte.
Beispiel
Im Beispiel steht %1 für [Sales] und %2 für [Profit].
RAWSQLAGG_BOOL("SUM( %1) >SUM( %2)”, [Sales], [Profit])
RAWSQLAGG_DATE("sql_expr”, [arg1], …[argN])
Gibt für einen angegebenen aggregierten SQL-Ausdruck ein Datumsergebnis zurück. Der SQL-Ausdruck wird direkt an die zugrunde liegende Datenbank übergeben. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Order Date].
Beispiel
RAWSQLAGG_DATE(“MAX(%1)”,
[Order Date])
RAWSQLAGG_DATETIME("sql_expr”, [arg1], …[argN])
Gibt für einen angegebenen aggregierten SQL-Ausdruck ein Datums- und Uhrzeitergebnis zurück. Der SQL-Ausdruck wird direkt an die zugrunde liegende Datenbank übergeben. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Delivery Date].
Beispiel
RAWSQLAGG_DATETIME(“MIN(%1)”, [Delivery Date])
RAWSQLAGG_INT(“sql_expr”, [arg1,] …[argN])
Gibt für einen angegebenen aggregierten SQL-Ausdruck eine Ganzzahl zurück. Der SQL-Ausdruck wird direkt an die zugrunde liegende Datenbank übergeben. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Sales].
Beispiel
RAWSQLAGG_INT(“500
+ SUM(%1)”, [Sales])
RAWSQLAGG_REAL(“sql_expr”, [arg1,] …[argN])
Gibt ein numerisches Ergebnis für einen angegebenen aggregierten SQL-Ausdruck zurück, der direkt an die zugrunde liegende Datenquelle übergeben wird. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Sales].
Beispiel
RAWSQLAGG_REAL(“SUM( %1)”, [Sales])
RAWSQLAGG_STR(“sql_expr”, [arg1,] …[argN])
Gibt eine Zeichenfolge für einen angegebenen aggregierten SQL-Ausdruck zurück, der direkt an die zugrunde liegende Datenquelle übergeben wird. Verwenden Sie %n im SQL-Ausdruck als Ersatz-Syntax für Datenbankwerte. In diesem Beispiel steht %1 für [Discount] (Rabatt).
Beispiel
RAWSQLAGG_STR(“AVG(%1)”,
[Discount])
Mithilfe räumlicher Funktionen können Sie erweiterte räumliche Analysen durchführen und räumliche Dateien mit Daten in anderen Formaten (wie Textdateien oder Tabellenkalkulationen) kombinieren.
AREA
| Syntax | AREA(Spatial Polygon, 'units') |
| Ausgabe | Zahl |
| Definition | Gibt die Gesamtfläche eines räumlichen Polygons (<spatial polygon>) zurück. |
| Beispiel | AREA([Geometry], 'feet') |
| Hinweise | Unterstützte Einheitennamen (müssen in der Berechnung in einfachen Anführungszeichen stehen, z. B
|
BUFFER
| Syntax | BUFFER(Spatial Point, distance, 'units')
|
| Ausgabe | Geometrie |
| Definition | Gibt für räumliche Punkte eine Polygonform zurück, die um einen räumlichen Punkt ( Berechnet bei Linienzügen die Polygone, die durch Einbeziehung aller Punkte innerhalb des Radiusabstands vom Linienzug gebildet werden. |
| Beispiel | BUFFER([Spatial Point Geometry], 25, 'mi') BUFFER(MAKEPOINT(47.59, -122.32), 3, 'km') BUFFER(MAKELINE(MAKEPOINT(0, 20),MAKEPOINT (30, 30)),20,'km')) |
| Hinweise | Unterstützte Einheitennamen (müssen in der Berechnung in einfachen Anführungszeichen stehen, z. B
|
DISTANCE
| Syntax | DISTANCE(SpatialPoint1, SpatialPoint2, 'units') |
| Ausgabe | Zahl |
| Definition | Gibt die Abstandsmessung zwischen zwei Punkten in einer bestimmten Einheit <unit> zurück. |
| Beispiel | DISTANCE([Origin Point],[Destination Point], 'km') |
| Hinweise | Unterstützte Einheitennamen (müssen in der Berechnung in einfachen Anführungszeichen stehen, z. B
|
| Datenbankseitige Einschränkungen | Diese Funktion kann nur mit einer Direktverbindung erstellt werden, funktioniert aber weiterhin, wenn eine Datenquelle in einen Extrakt umgewandelt wird. |
INTERSECTS
| Syntax | INTERSECTS (geometry1, geometry2) |
| Ausgabe | Boolesch |
| Definition | Gibt einen booleschen Wert (TRUE/FALSE) zurück, der angibt, ob sich zwei Geometrien räumlich überlappen. |
| Hinweise | Unterstützte Kombinationen: Punkt/Polygon, Linie/Polygon und Polygon/Polygon. |
MAKELINE
| Syntax | MAKELINE(SpatialPoint1, SpatialPoint2) |
| Ausgabe | Geometrie (Linie) |
| Definition | Erzeugt eine Linienmarkierung zwischen zwei Punkten |
| Beispiel | MAKELINE(MAKEPOINT(47.59, -122.32), MAKEPOINT(48.5, -123.1)) |
| Hinweise | Nützlich zum Erstellen von Ursprungs-Ziel-Karten. |
MAKEPOINT
| Syntax | MAKEPOINT(latitude, longitude, [SRID]) |
| Ausgabe | Geometrie (Punkt) |
| Definition | Konvertiert Daten aus Breiten- und Längengradspalten Wenn das optionale Argument |
| Beispiel | MAKEPOINT(48.5, -123.1) MAKEPOINT([AirportLatitude], [AirportLongitude]) MAKEPOINT([Xcoord],[Ycoord], 3493) |
| Hinweise |
Mit |
LENGTH
| Syntax | LENGTH(geometry, 'units') |
| Ausgabe | Zahl |
| Definition | Gibt die geodätische Pfadlänge der Linienzeichenfolge(n) in der <geometry> in der gegebenen Einheit <units> zurück. |
| Beispiel | LENGTH([Spatial], 'metres') |
| Hinweise | Das Ergebnis ist <NaN>, wenn das Geometrieargument keine Linienzeichenfolgen hat, obwohl andere Elemente zulässig sind. |
OUTLINE
| Syntax | OUTLINE(spatial polygon) |
| Ausgabe | Geometrie |
| Definition | Konvertiert eine Polygongeometrie in Linienzeichenfolgen. |
| Hinweise | Nützlich zum Erstellen einer separaten Ebene für einen Umriss, der anders gestaltet werden kann als die Füllung. Unterstützt Polygone innerhalb von Multipolygonen. |
SHAPETYPE
| Syntax | SHAPETYPE(geometry) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt eine Zeichenfolge zurück, die die Struktur des räumlichen Objekts <geometry> beschreibt, wie Empty, Point, MultiPoint, LineString, MultiLinestring, Polygon, MultiPolygon, Mixed und nicht unterstützte |
| Beispiel | SHAPETYPE(MAKEPOINT(48.5, -123.1)) = "Point" |
Reguläre Ausdrücke
REGEXP_REPLACE(Zeichenfolge, Muster, Ersetzung)
Gibt eine Kopie einer angegebenen Zeichenfolge zurück, wobei das reguläre Ausdrucksmuster durch die Ersetzungszeichenfolge ersetzt wird. Diese Funktion ist für Textdatei-, Hadoop Hive-, Google BigQuery-, PostgreSQL-, Tableau Data Extract-, Microsoft Excel-, Salesforce-, Vertica-, Pivotal Greenplum-, Teradata (ab Version 14.1), Snowflake- und Oracle-Datenquellen verfügbar.
Für Tableau-Datenextrakte müssen das Muster und der Ersatz Konstanten sein.
Informationen über die Syntax regulärer Ausdrücke finden Sie in der Dokumentation zu Ihrer Datenquelle. Bei Tableau-Extrakten stimmt die Syntax regulärer Ausdrücke mit den Standards von ICU (International Components for Unicode) überein. Hierbei handelt es sich um ein Open-Source-Projekt der ausgereiften C/C++- und Java-Bibliotheken für die Unicode-Unterstützung, die Softwareinternationalisierung und -globalisierung. Informationen finden Sie auf der Seite Reguläre Ausdrücke(Link wird in neuem Fenster geöffnet) im ICU-Onlinebenutzerhandbuch.
Beispiel
REGEXP_REPLACE('abc 123', '\s', '-') = 'abc-123'
REGEXP_MATCH(Zeichenfolge, Muster)
Gibt "true" zurück, wenn eine Unterzeichenfolge der angegebenen Zeichenfolge mit dem regulären Ausdrucksmuster übereinstimmt. Diese Funktion ist für Textdatei-, Google BigQuery-, PostgreSQL-, Tableau Data Extract-, Microsoft Excel-, Salesforce-, Vertica-, Pivotal Greenplum-, Teradata- (ab Version 14.1), Impala 2.3.0- (über Cloudera Hadoop-Datenquellen), Snowflake- und Oracle-Datenquellen verfügbar.
Für Tableau-Datumsextrakte muss das Muster eine Konstante sein.
Informationen über die Syntax regulärer Ausdrücke finden Sie in der Dokumentation zu Ihrer Datenquelle. Bei Tableau-Extrakten stimmt die Syntax regulärer Ausdrücke mit den Standards von ICU (International Components for Unicode) überein. Hierbei handelt es sich um ein Open-Source-Projekt der ausgereiften C/C++- und Java-Bibliotheken für die Unicode-Unterstützung, die Softwareinternationalisierung und -globalisierung. Informationen finden Sie auf der Seite Reguläre Ausdrücke(Link wird in neuem Fenster geöffnet) im ICU-Onlinebenutzerhandbuch.
Beispiel
REGEXP_MATCH('-([1234].[The.Market])-','\[\s*(\w*\.)(\w*\s*\])')=true
REGEXP_EXTRACT(Zeichenfolge, Muster)
Gibt die Teilmenge der Zeichenfolge zurück, die mit dem regulären Ausdrucksmuster übereinstimmt. Diese Funktion ist für Textdatei-, Hadoop Hive-, Google BigQuery-, PostgreSQL-, Tableau Data Extract-, Microsoft Excel-, Salesforce-, Vertica-, Pivotal Greenplum-, Teradata (ab Version 14.1), Snowflake- und Oracle-Datenquellen verfügbar.
Für Tableau-Datumsextrakte muss das Muster eine Konstante sein.
Informationen über die Syntax regulärer Ausdrücke finden Sie in der Dokumentation zu Ihrer Datenquelle. Bei Tableau-Extrakten stimmt die Syntax regulärer Ausdrücke mit den Standards von ICU (International Components for Unicode) überein. Hierbei handelt es sich um ein Open-Source-Projekt der ausgereiften C/C++- und Java-Bibliotheken für die Unicode-Unterstützung, die Softwareinternationalisierung und -globalisierung. Informationen finden Sie auf der Seite Reguläre Ausdrücke(Link wird in neuem Fenster geöffnet) im ICU-Onlinebenutzerhandbuch.
Beispiel
REGEXP_EXTRACT('abc 123', '[a-z]+\s+(\d+)') = '123'
REGEXP_EXTRACT_NTH(Zeichenfolge, Muster, Index)
Gibt die Teilmenge der Zeichenfolge zurück, die mit dem regulären Ausdrucksmuster übereinstimmt. Die Unterzeichenfolge wird der n-ten Erfassungsgruppe zugeordnet, wobei n dem angegebenen Index entspricht. Wenn der Index "0" lautet, wird die gesamte Zeichenfolge zurückgegeben. Diese Funktion ist für Textdatei-, PostgreSQL-, Tableau Data Extract-, Microsoft Excel-, Salesforce-, Vertica-, Pivotal Greenplum-, Teradata- (ab Version 14.1) und Oracle-Datenquellen verfügbar.
Für Tableau-Datumsextrakte muss das Muster eine Konstante sein.
Informationen über die Syntax regulärer Ausdrücke finden Sie in der Dokumentation zu Ihrer Datenquelle. Bei Tableau-Extrakten stimmt die Syntax regulärer Ausdrücke mit den Standards von ICU (International Components for Unicode) überein. Hierbei handelt es sich um ein Open-Source-Projekt der ausgereiften C/C++- und Java-Bibliotheken für die Unicode-Unterstützung, die Softwareinternationalisierung und -globalisierung. Informationen finden Sie auf der Seite Reguläre Ausdrücke(Link wird in neuem Fenster geöffnet) im ICU-Onlinebenutzerhandbuch.
Beispiel
REGEXP_EXTRACT_NTH('abc 123', '([a-z]+)\s+(\d+)', 2) = '123'
Hadoop Hive-spezifische Funktionen
Hinweis: Nur die Funktionen PARSE_URL und PARSE_URL_QUERY stehen für Cloudera Impala-Datenquellen zur Verfügung.
GET_JSON_OBJECT(JSON-Zeichenfolge, JSON-Pfad)
Gibt das JSON-Objekt innerhalb der JSON-Zeichenfolge basierend auf dem JSON-Pfad zurück.
PARSE_URL(Zeichenfolge, url_part)
Gibt eine Komponente der angegebenen URL zurück, wobei die Komponente durch url_part definiert ist. Gültige url_part-Werte beinhalten Folgendes: 'HOST', 'PATH', 'QUERY', 'REF', 'PROTOCOL', 'AUTHORITY', 'FILE' und 'USERINFO'.
Beispiel
PARSE_URL('http://www.tableau.com', 'HOST') = 'www.tableau.com'
PARSE_URL_QUERY(Zeichenfolge, Schlüssel)
Gibt den Wert des angegebenen Abfrageparameters in der angegebenen URL-Zeichenfolge zurück. Der Abfrageparameter ist durch den Schlüssel definiert.
Beispiel
PARSE_URL_QUERY('http://www.tableau.com?page=1&cat=4', 'page') = '1'
XPATH_BOOLEAN(XML-Zeichenfolge, Zeichenfolge für XPath-Ausdruck)
Gibt "true" zurück, wenn der XPath-Ausdruck mit einem Knoten übereinstimmt oder als "true" evaluiert wird.
Beispiel
XPATH_BOOLEAN('<values> <value id="0">1</value><value id="1">5</value>', 'values/value[@id="1"] = 5") = true
XPATH_DOUBLE(XML-Zeichenfolge, Zeichenfolge für XPath-Ausdruck)
Gibt den Gleitkommawert des XPath-Ausdrucks zurück.
Beispiel
XPATH_DOUBLE('<values><value>1.0</value><value>5.5</value> </values>', 'sum(value/*)') = 6.5
XPATH_FLOAT(XML-Zeichenfolge, Zeichenfolge für XPath-Ausdruck)
Gibt den Gleitkommawert des XPath-Ausdrucks zurück.
Beispiel
XPATH_FLOAT('<values><value>1.0</value><value>5.5</value> </values>','sum(value/*)') = 6.5
XATH_INT(XML-Zeichenfolge, Zeichenfolge für XPath-Ausdruck)
Gibt den numerischen Wert des XPath-Ausdrucks oder null zurück, wenn der XPath-Ausdruck nicht als Zahl evaluiert werden kann.
Beispiel
XPATH_INT('<values><value>1</value><value>5</value> </values>','sum(value/*)') = 6
XPATH_LONG(XML-Zeichenfolge, Zeichenfolge für XPath-Ausdruck)
Gibt den numerischen Wert des XPath-Ausdrucks oder null zurück, wenn der XPath-Ausdruck nicht als Zahl evaluiert werden kann.
Beispiel
XPATH_LONG('<values><value>1</value><value>5</value> </values>','sum(value/*)') = 6
XPATH_SHORT(XML-Zeichenfolge, Zeichenfolge für XPath-Ausdruck)
Gibt den numerischen Wert des XPath-Ausdrucks oder null zurück, wenn der XPath-Ausdruck nicht als Zahl evaluiert werden kann.
Beispiel
XPATH_SHORT('<values><value>1</value><value>5</value> </values>','sum(value/*)') = 6
XPATH_STRING(XML-Zeichenfolge, Zeichenfolge für XPath-Ausdruck)
Gibt den Text des ersten übereinstimmenden Knotens zurück.
Beispiel
XPATH_STRING('<sites ><url domain="org">http://www.w3.org</url> <url domain="com">http://www.tableau.com</url></sites>', 'sites/url[@domain="com"]') = 'http://www.tableau.com'
Google BigQuery-spezifische Funktionen
DOMAIN(Zeichenfolgen_URL)
Gibt im Fall einer URL-Zeichenfolge die Domäne als Zeichenfolge zurück.
Beispiel
DOMAIN('http://www.google.com:80/index.html') = 'google.com'
GROUP_CONCAT(Ausdruck)
Verkettet Werte aus den einzelnen Datensätzen zu einer einzelnen, durch Komma getrennten Zeichenfolge. Diese Funktion entspricht etwa der Funktion SUM() für Zeichenfolgen.
Beispiel
GROUP_CONCAT(Region) = "Central,East,West"
HOST(Zeichenfolgen_URL)
Gibt im Fall einer URL-Zeichenfolge den Hostnamen als Zeichenfolge zurück.
Beispiel
HOST('http://www.google.com:80/index.html') = 'www.google.com:80'
LOG2(Zahl)
Gibt den Logarithmus zur Basis 2 einer Zahl zurück.
Beispiel
LOG2(16) = '4.00'
LTRIM_THIS(Zeichnenfolge, Zeichenfolge)
Gibt die erste Zeichenfolge zurück und entfernt dabei alle vorangestellten Vorkommen der zweiten Zeichenfolge.
Beispiel
LTRIM_THIS('[-Sales-]','[-') = 'Sales-]'
RTRIM_THIS(Zeichenfolge, Zeichenfolge)
Gibt die erste Zeichenfolge zurück und entfernt dabei alle nachgestellten Vorkommen der zweiten Zeichenfolge.
Beispiel
RTRIM_THIS('[-Market-]','-]') = '[-Market'
TIMESTAMP_TO_USEC(Ausdruck)
Konvertiert innerhalb von Mikrosekunden einen TIMESTAMP-Datentyp in einen UNIX-Zeitstempel.
Beispiel
TIMESTAMP_TO_USEC(#2012-10-01 01:02:03#)=1349053323000000
USEC_TO_TIMESTAMP(Ausdruck)
Konvertiert einen UNIX-Zeitstempel innerhalb von Mikrosekunden in einen TIMESTAMP-Datentyp.
Beispiel
USEC_TO_TIMESTAMP(1349053323000000) = #2012-10-01 01:02:03#
TLD(Zeichenfolgen_URL)
Gibt im Fall einer URL-Zeichenfolge die Domäne der obersten Ebene sowie eine beliebige Länder-/Regionsdomäne in der URL zurück.
Beispiel
TLD('http://www.google.com:80/index.html') = '.com'
TLD('http://www.google.co.uk:80/index.html') = '.co.uk'
Möchten Sie mehr über Funktionen erfahren?
Lesen Sie die Themen über Funktionen(Link wird in neuem Fenster geöffnet).
Siehe auch
Tableau-Funktionen (alphabetisch)(Link wird in neuem Fenster geöffnet)