Zeichenfolgenfunktionen
In diesem Artikel werden Zeichenfolgenfunktionen sowie deren Nutzen in Tableau vorgestellt. Außerdem wird das Erstellen einer Zeichenfolgenberechnung anhand eines Beispiels dargestellt.
Warum werden Zeichenfolgenfunktionen verwendet?
Mit Zeichenfolgenfunktionen können Sie Zeichenfolgendaten ändern (d. h. aus Text bestehende Daten). Tableau verwendet beim Vergleich von Zeichenketten die aktuelle ICU-Bibliothek (International Components for Unicode). Die Art und Weise, wie Zeichenketten sortiert und verglichen werden, basiert sowohl auf der Sprache als auch auf dem Gebietsschema, und es ist möglich, dass sich die Visualisierungen ändern, da die ICU laufend aktualisiert wird, um die Sprachunterstützung zu verbessern.
Beispiel: Sie haben ein Feld, das die Vor- und Nachnamen Ihrer Kunden enthält. Eines der Listenelemente lautet beispielsweise: Jane Johnson. Sie können die Nachnamen aller Ihrer Kunden mit einer Zeichenfolgenfunktion in ein neues Feld ziehen.
Die Berechnung sieht in etwa so aus:
SPLIT([Customer Name], ' ', 2)
Daher gilt SPLIT('Jane Johnson' , ' ', 2) = 'Johnson'.
In Tableau verfügbare Zeichenfolgenfunktionen
ASCII
| Syntax | ASCII(string) |
| Ausgabe | Zahl |
| Definition | Gibt den ASCII-Code für das erste Zeichen einer Zeichenfolge (<string>) zurück. |
| Beispiel | ASCII('A') = 65 |
| Hinweise | Dies ist die Umkehrfunktion von CHAR. |
CHAR
| Syntax | CHAR(number) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt das Zeichen zurück für die ASCII-codierte <number>. |
| Beispiel | CHAR(65) = 'A' |
| Hinweise | Dies ist die Umkehrfunktion von ASCII. |
CONTAINS
| Syntax | CONTAINS(string, substring) |
| Ausgabe | Boolesch |
| Definition | Gibt TRUE zurück, wenn die Zeichenfolge die angegebene Teilzeichenfolge enthält. |
| Beispiel | CONTAINS("Calculation", "alcu") = true |
| Hinweise | Siehe auch die logische Funktion(Link wird in neuem Fenster geöffnet) IN sowie unterstützte RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
ENDSWITH
| Syntax | ENDSWITH(string, substring) |
| Ausgabe | Boolesch |
| Definition | Gibt TRUE zurück, wenn die Zeichenfolge mit der angegebenen Teilzeichenfolge endet. Nachfolgende Leerzeichen werden ignoriert. |
| Beispiel | ENDSWITH("Tableau", "leau") = true |
| Hinweise | Siehe auch die unterstützten RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
FIND
| Syntax | FIND(string, substring, [start]) |
| Ausgabe | Zahl |
| Definition | Gibt die Index-Position einer Teilzeichenfolge in einer Zeichenfolge zurück, oder 0, wenn die Teilzeichenfolge nicht gefunden wird. Das erste Zeichen in der Zeichenfolge ist Position 1. Wenn das optionale numerische Argument |
| Beispiel | FIND("Calculation", "alcu") = 2FIND("Calculation", "Computer") = 0FIND("Calculation", "a", 3) = 7FIND("Calculation", "a", 2) = 2FIND("Calculation", "a", 8) = 0 |
| Hinweise | Siehe auch die unterstützten RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
FINDNTH
| Syntax | FINDNTH(string, substring, occurrence) |
| Ausgabe | Zahl |
| Definition | Gibt die Position des n-ten Vorkommens einer Unterzeichenfolge in einer angegebenen Zeichenfolge zurück, wobei n durch das Argument "occurrence" definiert wird. |
| Beispiel | FINDNTH("Calculation", "a", 2) = 7 |
| Hinweise |
Siehe auch die unterstützten RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
LEFT
| Syntax | LEFT(string, number) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt den linken Teil einer Zeichenfolge mit der angegebenen Anzahl an Zeichen (<number>) zurück. |
| Beispiel | LEFT("Matador", 4) = "Mata" |
| Hinweise | Siehe auch MID und RIGHT. |
LEN
| Syntax | LEN(string) |
| Ausgabe | Zahl |
| Definition | Gibt die Länge der Zeichenfolge zurück. |
| Beispiel | LEN("Matador") = 7 |
| Hinweise | Nicht zu verwechseln mit der räumlichen Funktion(Link wird in neuem Fenster geöffnet) LENGTH. |
LOWER
| Syntax | LOWER(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die bereitgestellte <string> in Kleinbuchstaben zurück. |
| Beispiel | LOWER("ProductVersion") = "productversion" |
| Hinweise | Siehe auch UPPER und PROPER. |
LTRIM
| Syntax | LTRIM(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die bereitgestellte Zeichenfolge (<string>) zurück und entfernt dabei alle vorangestellten Leerzeichen. |
| Beispiel | LTRIM(" Matador ") = "Matador " |
| Hinweise | Siehe auch RTRIM. |
MAX
| Syntax | MAX(expression) oder MAX(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Maximalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MAX(4,7) = 7 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
MID
| Syntax | (MID(string, start, [length]) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt eine Zeichenfolge zurück, die an der angegebenen Wird das optionale numerische Argument |
| Beispiel | MID("Calculation", 2) = "alculation"MID("Calculation", 2, 5) ="alcul" |
| Hinweise | Siehe auch die unterstützten RegEx in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
MIN
| Syntax | MIN(expression) oder MIN(expr1, expr2) |
| Ausgabe | Gleicher Datentyp wie das Argument oder NULL , wenn ein Teil des Arguments null ist. |
| Definition | Gibt den Minimalwert der zwei Argumente zurück, die vom selben Datentyp sein müssen.
|
| Beispiel | MIN(4,7) = 4 |
| Hinweise | Für Zeichenfolgen
Bei Datenquellen einer Datenbank ist der Zeichenfolgenwert Für Datumsangaben Für Datumsangaben ist Als Aggregation
Als Vergleich
Siehe auch |
PROPER
| Syntax | PROPER(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die angegebene Zeichenfolge ( |
| Beispiel | PROPER("PRODUCT name") = "Product Name"PROPER("darcy-mae") = "Darcy-Mae" |
| Hinweise | Leerzeichen und nicht-alphanumerische Zeichen (z. B. Interpunktionszeichen) werden als Trennzeichen behandelt. |
| Datenbankseitige Einschränkungen | PROPER ist nur für einige Flatfiles und in Auszügen verfügbar. Wenn Sie PROPER in einer Datenquelle verwenden müssen, die dies ansonsten nicht unterstützt, sollten Sie die Verwendung eines Extrakts in Betracht ziehen. |
REPLACE
| Syntax | REPLACE(string, substring, replacement |
| Ausgabe | Zeichenfolge |
| Definition | Sucht nach <string> für <substring> und ersetzt diesen durch <replacement>. Falls die <substring> nicht gefunden wird, bleibt die Zeichenfolge unverändert. |
| Beispiel | REPLACE("Version 3.8", "3.8", "4x") = "Version 4x" |
| Hinweise | Siehe auch REGEXP_REPLACE in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
RIGHT
| Syntax | RIGHT(string, number) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt den rechten Teil einer Zeichenfolge mit der angegebenen Anzahl an Zeichen (<number>) zurück. |
| Beispiel | RIGHT("Calculation", 4) = "tion" |
| Hinweise | Siehe auch LEFT und MID. |
RTRIM
| Syntax | RTRIM(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die bereitgestellte Zeichenfolge (<string>) zurück und entfernt dabei alle nachgestellten Leerzeichen. |
| Beispiel | RTRIM(" Calculation ") = " Calculation" |
| Hinweise | Siehe auch LTRIM und TRIM. |
SPACE
| Syntax | SPACE(number) |
| Ausgabe | Zeichenfolge (eigentlich nur Leerzeichen) |
| Definition | Gibt eine Zeichenfolge zurück, die aus der angegebenen Anzahl an Leerzeichen besteht. |
| Beispiel | SPACE(2) = " " |
SPLIT
| Syntax | SPLIT(string, delimiter, token number) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt eine Unterzeichenfolge von einer Zeichenfolge zurück und unterteilt die Zeichenfolge anhand von Trennzeichen in eine Abfolge aus Token. |
| Beispiel | SPLIT ("a-b-c-d", "-", 2) = "b"SPLIT ("a|b|c|d", "|", -2) = "c" |
| Hinweise | Die Zeichenfolge wird als eine sich abwechselnde Sequenz aus Trennzeichen und Token interpretiert. Bei der Zeichenfolge
Siehe auch unterstützte REGEX in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
| Datenbankseitige Einschränkungen | Die Befehle "Teilen" und "Benutzerdefiniertes Teilen" stehen für die folgenden Datenquellentypen zur Verfügung: Tableau-Datenextrakte, Microsoft Excel, Textdatei, PDF-Datei, Salesforce, OData, Microsoft Azure Market Place, Google Analytics, Vertica, Oracle, MySQL, PostgreSQL, Teradata, Amazon Redshift, Aster Data, Google Big Query, Cloudera Hadoop Hive, Hortonworks Hive und Microsoft SQL Server. Einige Datenquellen setzen Limits in Bezug auf das Aufteilen einer Zeichenfolge. Weitere Informationen dazu finden Sie unter den Einschränkungen der SPLIT-Funktion weiter unten. |
STARTSWITH
| Syntax | STARTSWITH(string, substring) |
| Ausgabe | Boolesch |
| Definition | Gibt "true" zurück, wenn string mit substring beginnt. Vorgestellte Leerzeichen werden ignoriert. |
| Beispiel | STARTSWITH("Matador, "Ma") = TRUE |
| Hinweise | Siehe auch CONTAINS sowie unterstützte REGEX in der Dokumentation zu Zusatzfunktionen(Link wird in neuem Fenster geöffnet). |
TRIM
| Syntax | TRIM(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die bereitgestellte Zeichenfolge (<string>) zurück und entfernt dabei alle vor- und nachgestellten Leerzeichen. |
| Beispiel | TRIM(" Calculation ") = "Calculation" |
| Hinweise | Siehe auch LTRIM und RTRIM. |
UPPER
| Syntax | UPPER(string) |
| Ausgabe | Zeichenfolge |
| Definition | Gibt die angegebene Zeichenfolge (<string>) in Großbuchstaben zurück. |
| Beispiel | UPPER("Calculation") = "CALCULATION" |
| Hinweise | Siehe auch PROPER und LOWER. |
Erstellen einer Zeichenfolgenberechnung
Sehen Sie sich das Beispiel unten an, um mehr über das Erstellen einer Zeichenfolgenberechnung zu erfahren.
Stellen Sie in Tableau Desktop eine Verbindung zur standardmäßig in Tableau enthaltenen gespeicherten Datenquelle Beispiel – Superstore her.
Navigieren Sie zu einem Arbeitsblatt.
Ziehen Sie den Wert Bestell-ID aus dem Datenfenster unter Dimensionen in den Container Zeilen.
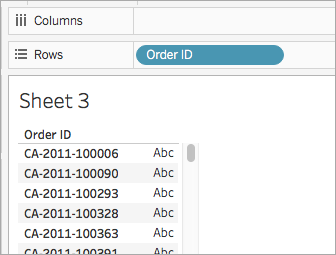
Beachten Sie, dass jede Bestell-ID Werte für das Land (zum Beispiel CA und US), das Jahr (2011) und die Bestellnummer (100006) enthält. In diesem Beispiel erstellen Sie eine Berechnung, um nur die Bestellnummer aus dem Feld zu extrahieren.
Wählen Sie Analyse > Berechnetes Feld erstellen aus.
Gehen Sie in dem anschließend geöffneten Berechnungs-Editor wie folgt vor:
Geben Sie dem berechneten Feld den Namen Bestell-ID-Nummern.
Geben Sie die folgende Formel ein:
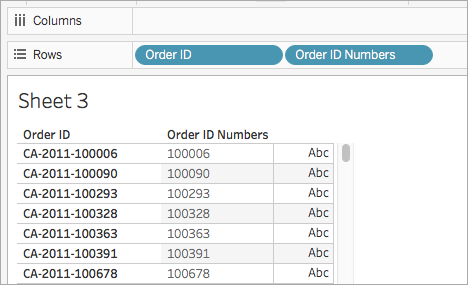
RIGHT([Order ID], 6)Diese Formel entnimmt der rechten Seite der Zeichenfolge die festgelegten Zahlen (6) und zieht diese in ein neues Feld.
Daher gilt
RIGHT('CA-2011-100006' , 6)= '100006'.Klicken Sie auf OK, wenn Sie fertig sind.
Das neue berechnete Feld wird im Bereich Daten unter Dimensionen angezeigt. Wie bei Ihren anderen Feldern ist die Verwendung in mindestens einer Visualisierung möglich.
Ziehen Sie das Feld Bestell-ID-Nummern im Bereich Daten auf den Container Zeilen. Platzieren Sie es rechts neben Bestell-ID.
Achten Sie darauf, wie sich die Felder nun unterscheiden.
SPLIT-Einschränkungen nach Datenquelle
Einige Datenquellen erheben Begrenzungen in Bezug auf das Aufteilen einer Zeichenfolge. Die folgende Tabelle zeigt, welche Datenquellen negative Tokennummern (Aufteilung von rechts) unterstützen und ob eine Begrenzung der Anzahl der pro Datenquelle zulässigen Aufteilungen vorliegt.
Eine SPLIT-Funktion, die eine negative Tokennummer festlegt und mit anderen Datenquellen zulässig wäre, wird bei diesen Datenquellen diesen Fehler zurückgeben: “Das Aufteilen von rechts wird von der Datenquelle nicht unterstützt.”
| Datenquelle | Links-/Rechtsbeschränkungen | Maximale Anzahl der Aufteilungen | Versionsbeschränkungen |
| Tableau Data Extract | Beide | Unbegrenzt | |
| Microsoft Excel | Beide | Unbegrenzt | |
| Textdatei | Beide | Unbegrenzt | |
| Salesforce | Beide | Unbegrenzt | |
| OData | Beide | Unbegrenzt | |
| Google Analytics | Beide | Unbegrenzt | |
| Tableau-Datenserver | Beide | Unbegrenzt | Wird in Version 9.0 unterstützt. |
| Vertica | Nur links | 10 | |
| Oracle | Nur links | 10 | |
| MySQL | Beide | 10 | |
| PostgreSQL | Links nur für Version vor 9.0, beide für Version 9.0 und höher | 10 | |
| Teradata | Nur links | 10 | Version 14 und höher |
| Amazon Redshift | Nur links | 10 | |
| Aster Database | Nur links | 10 | |
| Google BigQuery | Nur links | 10 | |
| Hortonworks Hadoop Hive | Nur links | 10 | |
| Cloudera Hadoop | Nur links | 10 | Impala wird ab der Version 2.3.0 unterstützt. |
| Microsoft SQL Server | Beide | 10 | 2008 und höher |
Siehe auch
Tableau-Funktionen (alphabetisch)