Extract Your Data
A data extract is a subset of information that is saved separately from the original dataset. It serves two purposes: to enhance performance and to utilize Tableau features that may not be available or supported in the original data. By creating a data extract, you can effectively reduce the overall data volume by applying filters and setting other limitations.
Once a data extract is created, it can be refreshed with the latest data from the original source. During the refresh process, you have the flexibility to choose between a full refresh, which replaces all existing content in the extract, or an incremental refresh, which only includes new rows since the previous refresh.
Note: Starting from version 2024.1, Tableau introduces a feature that enables users to perform incremental refreshes on extracts using a non-unique key column.
Benefits of Extracts
-
Handling large datasets: Extracts can handle massive amounts of data, even reaching billions of rows. This allows users to work with extensive datasets efficiently.
-
Improved performance: Interacting with views that utilize extract data sources results in better performance compared to views connected directly to the original data. Extracts optimize query performance, resulting in faster data analysis and visualization.
-
Enhanced functionality: Extracts provide access to additional Tableau functionality that may not be available or supported by the original data source.
For instance, users can leverage extracts to compute Count Distinct, enabling more advanced calculations and analysis.
-
Offline data access (Tableau Desktop): Extracts allow for offline access to data. This means that even when the original data source isn't available, users can still save, manipulate, and work with the data locally.
Create an extract
There are multiple options available within your Tableau workflow to create an extract, but the main approach is explained below.
-
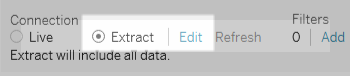
After you connect to your data and set up the data source on the Data Source page, in the upper-right corner, select Extract, and then select the Edit link to open the Extract Data dialog box.
-
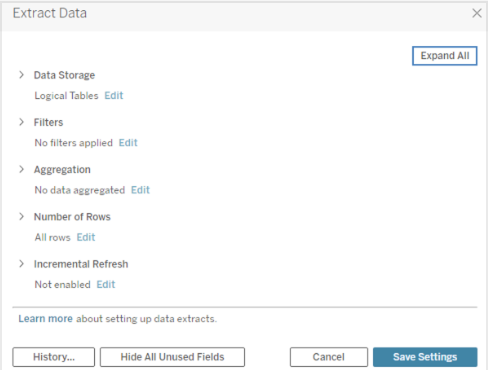
Under Data Storage, select either Logical Tables or Physical Tables. For assistance with this step see the Data Storage section.
-
Expand Filters to set up filters to limit how much data gets extracted based on fields and their values.
-
Select Aggregate data for visible dimensions to aggregate the measures using their default aggregation.
-
(Optional) Select Roll up dates to a specified date level such as Year, Month, etc.
-
Select the number of rows you want to extract. You can extract All rows, Sample, or the Top N rows.
-
Select the Incremental refreshbox, and then specify the table to refresh and a column in the database that will be used to identify new rows.
-
When finished, choose Save Settings.
-
Select the sheet tab. This initiates the creation of the extract.
-
Next, select a location to save the extract.
-
Enter an extract file name.
-
Select Save. If the Save dialog box doesn't display, see the Troubleshoot extracts section.

Extract field descriptions
You can configure numerous fields when creating an extract. This section walks you through each field.
Data Storage
Under Data Storage you can select either Logical or Physical tables. Logical tables store data in one extract table for each logical table in the data source. On the other hand, physical tables store data in one extract table for each physical table in the data source.
Logical tables
If you want to limit the amount of data in your extract and use additional extract properties like filters, aggregation, or Top N, you should select Logical Tables.
-
This option also works well when your data includes pass-through functions (RAWSQL).
-
Tableau uses Logical Tables as the default structure for storing extract data.
-
If you choose this option and your extract includes joins, the joins will be applied when the extract is created.
Physical tables
If your extract consists of tables combined with equality joins and meets the Conditions for using the Physical Tables option, you should select Physical Tables. This option performs joins at query time and can potentially improve performance and reduce the size of the extract file.
Considerations for using the Physical Tables option. To store your extract using the Physical Tables option, the data in your extract must meet all of the following conditions.
-
All joins between physical tables are equality (=) joins.
-
Data types of the columns used for relationships or joins are identical.
-
No pass-through functions (RAWSQL) used.
-
No incremental refresh configured.
-
No extract filters configured.
-
No Top N or sampling configured.
-
When the extract is stored as physical tables, you can't append data to it.
-
For logical tables, you can't append data to extracts that have more than one logical table.
Tips for using the physical tables option
Tableau generally recommends that you use the default data storage option, Logical Tables, when setting up and working with extracts. In many cases, some of the features you need for your extract, like extract filters, are only available to you if you use the Logical Tables option.
Physical Tables option for extracts that are larger than expected
The Physical Tables option should be used sparingly to help with specific situations such as when your data source meets the Conditions for using the Physical Tables option and the size of your extract is larger than expected. To determine if the extract is larger than it should be, the sum of rows in the extract using the Logical Tables option must be higher than the sum of rows of all the combined tables before the extract has been created. If you encounter this scenario, try using the Physical Tables option instead.
Alternative filtering suggestions when using the physical tables option
When using the Physical Tables option, other options to help reduce the data in your extract, like extract filters, aggregation, Top N and Sampling are disabled. If you need to reduce the data in an extract that uses the Physical Tables option, consider filtering the data before it is brought into Tableau Desktop using one of the following suggestions:
Connect to your data and define filters using custom SQL
Instead of connecting to a database table, connect to your data using custom SQL instead. When creating your custom SQL query, make sure that it contains the appropriate level of filtering that you need to reduce the data in your extract. For more information about custom SQL in Tableau Desktop, see Connect to a Custom SQL Query.
Define a view in the database
If you have write access to your database, consider defining a database view that contains just the data you need for your extract and then connect to the database view from Tableau Desktop.
Row-level security with extracts
If you want to secure extract data at the row level, using the Physical Tables option is the recommended way to achieve this scenario. For more information about row-level security in Tableau, see Restrict Access at the Data Row Level.
General table considerations
Both the Logical Tables and Physical Tables options only affect how the data in your extract is stored. The options don't affect how tables in your extract are displayed on the Data Source page.
For example, suppose your extract consists of one logical table that contains three physical tables.
If you directly open the extract (.hyper) file that has been configured to use the default option, Logical Tables, you see one table listed on the Data Source page.
However, if you open the extract using the packaged data source (.tdsx) file or the data source (.tdsx) file with its corresponding extract (.hyper) file, you see all three tables that comprise the extract on the Data Source page.
Filters
Use filters to set up filters to limit how much data gets extracted based on fields and their values.
Aggregation
Aggregation allows you to aggregate measures. You can also select Roll up dates to a specified date level such as Year, Month, etc. The examples below show how the data will be extracted for each aggregation option you can choose.
| Original data |
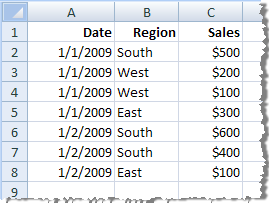
|
Each record is shown as a separate row. There are seven rows in your data. |
| Aggregate data for visible dimensions
(no roll up) |
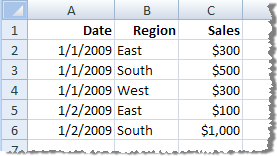
|
Records with the same date and region have been aggregated into a single row. There are five rows in the extract. |
| Aggregate data for visible dimensions (roll up dates to Month) |
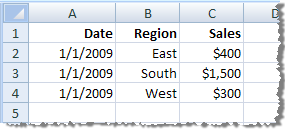
|
Dates have been rolled up to the Month level and records with the same region have been aggregated into a single row. There are three rows in the extract. |
Number of rows
You can extract All rows or the Top N rows. Tableau first applies any filters and aggregation and then extracts the number of rows from the filtered and aggregated results. The number of rows options depend on the type of data source you are extracting from. You might not see the Sampling option in the Extract Data dialog box because some data sources don't support sampling.
Note(s):Any fields that you hide first in the Data Source page or on the sheet tab will be excluded from the extract. Click the Hide All Unused Fields button to remove the hidden fields from the extract.
Incremental Refresh
Most data sources support an incremental refresh. Rather than refreshing the entire extract, you can configure a refresh to add only the rows that are new since the previous time you extracted the data.
For example, you may have a data source that is updated daily with new sales transactions. Rather than rebuild the entire extract each day, you can just add the new transactions that occurred that day.
Incremental Refresh and Advanced Settings tips
This section will help you with tips to prevent errors you can encounter when setting up these features.
Incremental Refresh:
-
In Number of Rows, you need to select All Rows.
-
Incremental Refresh isn't available if you enable Aggregation.
Advanced Settings:
-
Advanced Settings aren't compatible with Filters.
Extract tips
Save your workbook to preserve the connection to the extract
After you create an extract, the workbook begins to use the extract version of your data. However, the connection to the extract version of your data isn’t saved until you save the workbook. This means if you close the workbook without saving the workbook first, the workbook will connect to the original data source the next time you open it.
Toggle between sampled data and entire extract
When you're working with a large extract, it can be helpful to create a smaller sample of the data. This allows you to set up your view without having to run lengthy queries every time you add a field to your analysis. You can easily switch between using the sample data and the complete data source by selecting the appropriate option in the Data menu.
Don't connect directly to the extract
When you save extracts to your computer, you can directly connect to them using a new Tableau Desktop. However, it isn't recommended for a few of the following reasons:
The names of the tables may be different.
Extracts use special naming to ensure that each table has a unique name, which might be hard to understand.
You can’t update or refresh the extract.
When you connect directly to an extract, Tableau considers it as the original source of data, rather than a copy. This means you can’t link it back to your original data source.
The structure and relationships between tables will be lost.
The arrangement and connections between tables are stored in the .tds file, not in the .hyper file. Therefore, when you connect directly to the .hyper file, you lose this information. If you use logical tables storage for the extract, you won't see any references to the original physical tables.
Remove the extract from the workbook
You can remove an extract at anytime by selecting the extract data source on the Data menu and then selecting . When you remove an extract, you can choose to Remove the extract from the workbook only or Remove and delete the extract file. The latter option will delete the extract from your hard drive.
See extract history (Tableau Desktop)
You can see when the extract was last updated and other details by selecting a data source on the Data menu and then selecting .
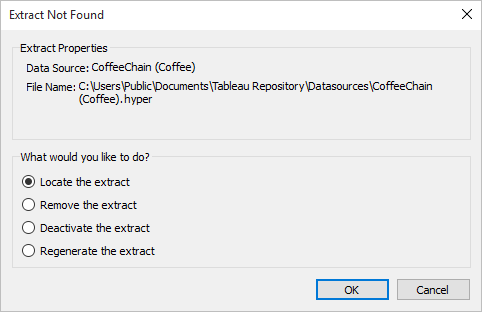
If you open a workbook that is saved with an extract and Tableau can't locate the extract, select one of the following options in the Extract Not Found dialog box when prompted:
-
Locate the extract: Select this option if the extract exists but not in the location where Tableau originally saved it. Click OK to open an Open File dialog box where you can specify the new location for the extract file.
-
Remove the extract: Select this option if you have no further need for the extract. This is equivalent to closing the data source. All open worksheets that reference the data source are deleted.
-
Deactivate the extract: Use the original data source from which the extract was created, instead of the extract.
-
Regenerate the extract: Recreates the extract. All filters and other customizations you specified when you originally created the extract are automatically applied.
Troubleshoot extracts
-
Creating an extract takes a long time: Depending on the size of your data set, creating an extract can take a long time. However, after you have extracted the data and saved it to your computer, performance can improve.
-
Extract is not created: If your data set contains a really large number of columns (e.g., in the thousands), in some cases Tableau might not be able to create the extract. If you encounter problems, consider extracting fewer columns or restructuring the underlying data.
-
Save dialog does not display or extract is not created from a .twbx: If you follow the above procedure to extract data from a packaged workbook, the Save dialog doesn't display. When an extract is created from a packaged workbook (.twbx), the extract file is automatically stored in the package of files associated with the packaged workbook. To access the extract file that you created from the packaged workbook, you must unpackage the workbook. For more information, see Packaged Workbooks.
Extract feature updates
Incremental Refresh
Starting from version 2024.1, Tableau introduces a feature that enables users to perform incremental refreshes on extracts using a non-unique key column. There is a new UI that supports these advanced settings.
This update introduces an additional step in the process. During an incremental refresh, Tableau first removes rows from the extract that match the previously recorded highest value. Subsequently, Tableau queries for all rows that have a value higher than or equal to the previous highest value. This approach ensures that any deleted rows are accounted for, along with any newly added ones.
Extracts in the web
Beginning with version 2020.4, extracts are available in web authoring and content server. Now, you no longer have to use Tableau Desktop to extract your data sources. For more information, see Create Extracts on the Web.
Logical and physical table extracts
With the introduction of logical tables and physical tables in the Tableau data model in version 2020.2, extract storage options have changed from Single Table and Multiple Tables, to Logical Tables and Physical Tables. These options better describe how extracts will be stored. For more information, see Extract Your Data.
Deprecation of .tde format
Note: Beginning in March 2023, extracts using the .tde format are deprecated in Tableau Cloud, Tableau Public, and Tableau Server (version 2023.1.0). For more information, see Extract Upgrade to .hyper Format.
Beginning with version 10.5, when you create a new extract it uses the .hyper format. Extracts in the .hyper format take advantage of the improved data engine, which supports faster analytical and query performance for larger data sets.
Similarly, when an extract-related task is performed on a .tde extract using version 10.5 and later, the extract is upgraded to a .hyper extract. After a .tde extract is upgraded to a .hyper extract, it can't be reverted back to .tde extract. For more information, see Extract Upgrade to .hyper Format.
Changes to values and marks in the view
To improve extract efficiency and scalability, values in extracts can be computed differently in versions 10.5 and later compared to versions 10.4 and earlier. Changes to how the values are computed can affect the way marks in your view are populated. In some rare cases, the changes can cause your view to change shape or become blank. These changes can also apply to multi-connection data sources, data sources that use live connections to filed-based data, data sources that connect to Google Sheets data, cloud-based data sources, extract-only data sources, and WDC data sources.
To get an idea of some of the differences you might see in your view using version 2022.4, see the sections below.
Format of date and date time values
In versions 10.5 and later, extracts are subject to more consistent and stricter rules around how date strings are interpreted through the DATE, DATETIME, and DATEPARSE functions. This affects how dates are parsed, or the date formats and patterns that are allowed for these functions. More specifically, the rules can be generalized as the following:
- Dates are evaluated and then parsed by column, not by row.
- Dates are evaluated and then parsed based on the locale of where the workbook was created, not on locale of the computer where the workbook is opened.
These new rules allow extracts to be more efficient and to produce results that are consistent with commercial databases.
However, because of these rules, particularly in international scenarios where the workbook is created in a locale different from the locale that the workbook is opened in or the server that the workbook is published to, you might see that 1.) date and datetime values change to different date and datetime values or 2.) date and datetime values change to Null. When your date and datetime values change to different date and datetime values or become Null, it's often an indication that there are issues with the underlying data.
Here are some common reasons why you might see changes to your date and datetime values in your extract data source using version 10.5 and later.
|
Common causes of changes to date/datetime values |
Common causes of null values |
|---|---|
|
|
Date scenario 1
Suppose you have a workbook created in an English locale that uses .tde extract data source. The table below shows a column of string data contained in the extract data source.
| 10/31/2018 |
| 31/10/2018 |
|
12/10/2018 |
Based on the particular English locale, the format of the date column was determined to follow the MDY (month, day, and year) format. The following tables show what Tableau displays based on this locale when the DATE function is used to convert string values into date values.
| October 31, 2018 |
| October 31, 2018 |
| December 10, 2018 |
If the extract is opened in a German locale, you see the following:
| 31 Oktober 2018 |
| 31 Oktober 2018 |
| 12 Oktober 2018 |
However, after the extract is opened in a German locale using version 10.5 and later, the DMY (day, month, and year) format of the German locale is strictly enforced and causes a Null value because one of the values doesn't follow DMY format.
| Null |
| October 31, 2018 |
| October 12, 2018 |
Date scenario 2
Suppose you have another workbook created in an English locale that uses a .tde extract data source. The table below shows a column of numeric date data contained in the extract data source.
| 1112018 |
| 1212018 |
| 1312018 |
| 1412018 |
Based on the particular English locale, the format of the date column was determined to follow the MDY (month, day, and year) format. The following tables show what Tableau displays based on this locale when the DATE function is used to convert the numeric values into date values.
| 11/1/2018 |
| 12/1/2018 |
| Null |
| Null |
Date scenario 3
Suppose you have a workbook that uses a .tde extract data source. The table below shows a column of string data contained in the extract data source.
| 2018-10-31 |
| 2018-31-10 |
|
2018-12-10 |
| 2018-10-12 |
Because the date uses the ISO format, the date column always follows the YYYY-MM-DD format. The following tables show what Tableau displays when the DATE function is used to convert string values into date values.
| October 10, 2018 |
| Null |
| December 10, 2018 |
| October 12, 2018 |
Note: In versions 10.4 (and earlier), ISO format and other date formats could have produced differing results depending on the locale of where the workbook was created. In an English locale for example, both 2018-12-10 and 2018/12/10 could produce December 12, 2o18. However, in a German locale 2018-12-10 could produce December 12, 2018 and 2018/12/10 could produce October 12, 2018.
Sort order and case sensitivity
Extracts have collation support and therefore can more appropriately sort string values that have accents or are cased differently.
For example, suppose you have a table of string values. In terms of sort order, this means that a string value like Égypte is now appropriately listed after Estonie and before Fidji.
About Excel data:
With regard to casing, this means that how Tableau stores values have changed between version 10.4 (and earlier) and version 10.5 (and later). However, the rules for sorting and comparing values haven't. In version 10.4 (and earlier), string values like "House," "HOUSE," and "houSe" are treated the same and stored with one representative value. In version 10.5 (and later), the same string values are considered unique and therefore stored as individual values. For more information, see Changes to the way values are computed.
Breaking ties in Top N queries
When a Top N query in your extract produces duplicate values for a specific position in a rank, the position that breaks the tie can be different when using version 10.5 and later. For example, suppose you create a top 3 filter. Positions 3, 4, and 5 have the same values. When using version 10.4 and earlier, the top filter can return 1, 2, and 3 positions. However, when using version 10.5 and later, the top filter can return 1, 2, and 5 positions.
Precision of floating-point values
Extracts are better at taking advantage of the available hardware resources on a computer and therefore able to perform mathematical operations in a highly parallel way. Because of this, real numbers can be aggregated by .hyper extracts in different order. When numbers are aggregated in different order, you might see different values in your view after the decimal point each time the aggregation is computed. This is because floating-point addition and multiplication is not necessarily associative. That is, (a + b) + c isn't necessarily the same as a + (b + c). Also, real numbers can be aggregated in different order because floating-point multiplication isn't necessarily distributive. That is, (a x b) x c isn't necessarily the same as a x b x c. This type of floating-point rounding behavior in .hyper extracts resemble that of floating-point rounding behavior in commercial databases.
For example, suppose your workbook contains a slider filter on an aggregated field comprised of floating point values. Because the precision of floating-point values have changed, the filter might now exclude a mark that defines the upper or lower bound of the filter range. The absence of these numbers could cause a blank view. To resolve this issue, move the slider on the filter or remove and add the filter again.
Accuracy of aggregations
Extracts optimize for large data sets by taking better advantage of the available hardware resources on a computer and therefore able to compute aggregations in a highly parallel way. Because of this, aggregations performed by .hyper extracts can resemble the results from commercial databases more than the results from software that specializes in statistical computations. If you’re working with a small data set or need a higher level of accuracy, consider performing aggregations through reference lines, summary card statistics, or table calculation functions like variance, standard deviation, correlation, or covariance.
About the Compute Calculations Now option for extracts
If the Compute Calculations Now option was used in a .tde extract using an earlier version of Tableau Desktop, certain calculated fields were materialized and therefore computed in advance and stored in the extract. If you upgrade the extract from a .tde extract to a .hyper extract, the previously materialized calculations in your extract aren't included. You must use the Compute Calculations Now option again to ensure that materialized calculations are a part of the extract after the extract upgrade. For more information, see Materialize Calculations in Your Extracts.
New Extract API
You can use the Extract API 2.0 to create .hyper extracts. For tasks that you previously performed using the Tableau SDK, such as publishing extracts, you can use the Tableau Server REST API or the Tableau Server Client (Python) library. For refresh tasks, you can use the Tableau Server REST API as well. For more information, see Tableau Hyper API.