Google BigQuery
Cet article décrit comment connecter Tableau à des données Google BigQuery et configurer la source de données.
Remarque : certaines des fonctionnalités et personnalisations répertoriées dans cet article ne sont pas prises en charge dans Tableau Prep Builder. Pour plus d’informations sur la connexion aux données dans Prep Builder, consultez Se connecter aux données(Le lien s’ouvre dans une nouvelle fenêtre).
Avant de commencer
Avant de démarrer, rassemblez les informations de connexion suivantes :
- E-mail ou téléphone, et mot de passe Google BigQuery
Recommandation
Configurer un client OAuth personnalisé pour utiliser les stratégies informatiques de votre entreprise
Vous pouvez contrôler entièrement votre configuration OAuth en fonction de vos propres politiques informatiques avec un client OAuth personnalisé. L’option d’utiliser votre propre client OAuth vous évite d’être lié aux cycles de publication de Tableau et au calendrier de rotation des clients OAuth de Tableau. Pour plus d’informations sur la configuration de votre propre client OAuth, consultez Configurer OAuth personnalisé pour un site.
Établir la connexion et configurer la source des données
Remarque : pour utiliser les informations d’identification du compte de service pour une nouvelle source de données Google BigQuery, la connexion doit être créée dans Tableau Desktop.
Démarrez Tableau et sous Connexion, sélectionnez Google BigQuery.
Appliquez l’une des 2 options suivantes pour continuer.
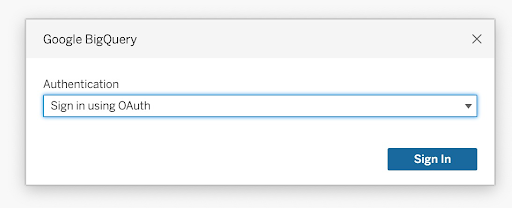
Option 1 :
- Dans Authentification, sélectionnez Se connecter avec OAuth.
- Cliquez sur Connexion.
- Entrez votre mot de passe pour continuer.
- Sélectionnez Accepter pour autoriser Tableau à accéder à vos données Google BigQuery. Vous serez invité à fermer le navigateur.
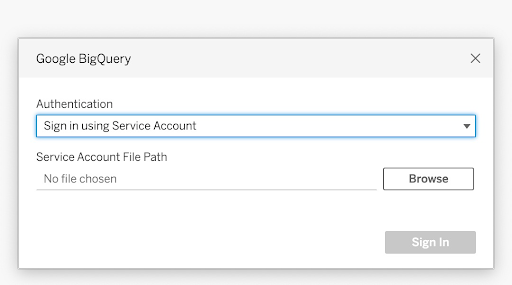
Option 2 :
Conseil : si vous utilisez Tableau Server ou Tableau Cloud pour la publication, vous devez commencer par vous connecter au produit que vous utilisez, puis ajouter vos informations d’identification Google BigQuery enregistrées dans les paramètres du compte. Cela évitera une « erreur d’informations d’identification non valides ».
- Dans Authentification, sélectionnez Se connecter avec un fichier de compte de service (fichier JSON).
- Entrez le chemin d’accès du fichier ou utilisez le bouton Parcourir pour le rechercher.
- Cliquez sur Connexion.
- Entrez votre mot de passe pour continuer.
- Sélectionnez Accepter pour autoriser Tableau à accéder à vos données Google BigQuery. Vous serez invité à fermer le navigateur.
Sur la page de la source de données, procédez comme suit :
(Facultatif) Sélectionnez le nom de la source de données par défaut en haut de la page, puis tapez un nom de source de données unique pour l’utiliser dans Tableau. Par exemple, utilisez une convention pertinente d’appellation de la source de données qui aide d’autres utilisateurs de la source de données à déduire à quelle source de données se connecter.
(Facultatif) Dans la liste déroulante Billing Project, sélectionnez un projet de facturation. Si vous ne sélectionnez pas un projet de facturation,
EmptyProjectapparaît dans le champ une fois que vous avez sélectionné les champs restants.Dans la liste déroulante Project, sélectionnez un projet. Vous pouvez également sélectionner publicdata pour vous connecter à l’exemple de données dans BigQuery.
Dans la liste déroulante Dataset, sélectionnez un jeu de données.
Sous Table, sélectionnez une table.
Utilisez SQL personnalisé pour vous connecter à une requête spécifique plutôt qu’à la source de données entière. Pour plus d’informations, voir Se connecter à une requête SQL personnalisée.
Remarques :
- Google BigQuery a modifié la prise en charge de BigQuery legacy SQL (BQL) en SQL standard. Vos classeurs sont mis à niveau de manière à prendre en charge SQL standard lorsque vous les ouvrez dans Tableau.
- En raison du volume important de données existantes dans BigQuery, Tableau recommande d’utiliser l’option de connexion en direct.
- La fonction Radians() n’est pas prise en charge dans Google BigQuery.
Utiliser les attributs de personnalisation pour améliorer les performances de requête
Remarque : Les attributs de personnalisation ne sont pas actuellement pris en charge dans Tableau Prep Builder.
Vous pouvez utiliser les attributs de personnalisation pour améliorer les performances des ensembles de résultats volumineux renvoyés par BigQuery à Tableau Cloud, Tableau Server, et sur Tableau Desktop.
Vous pouvez inclure les attributs de personnalisation dans votre classeur ou votre source de données publié(e), tant que vous spécifiez les attributs avant de publier le classeur ou la source de données sur Tableau Cloud ou Tableau Server.
Utiliser les attributs de personnalisation Google BigQuery
Les attributs de personnalisation acceptent les valeurs de nombre entier et affectent à la fois les requêtes en direct et les actualisations d’extrait pour la connexion spécifiée.
Les attributs suivants sont particulièrement utiles pour améliorer les performances des ensembles de résultats volumineux :
| bq-fetch-tasks | Nombre de tâches d’arrière-plan parallèles à utiliser lors de la récupération de données à l’aide de HTTP. La valeur par défaut est 10. |
| bq-large-fetch-rows | Nombre de lignes à récupérer dans chaque lot pour des requêtes de spouling. La valeur par défaut est 50000. |
Les attributs suivants sont également disponibles et utilisés pour les petites requêtes :
| bq-fetch-rows | Nombre de lignes à récupérer dans chaque lot pour des requêtes sans spouling. La valeur par défaut est 10000. |
| bq-response-rows | Nombre de lignes renvoyées dans des requêtes sans lots ni spouling. La valeur par défaut est 10000. |
Ce paramètre de capacité accepte les valeurs yes ou no, et peut être utile lors de tests :
| CAP_BIGQUERY_FORCE_SPOOL_JOB | Forcer toutes les requêtes à utiliser l’approche de table temporaire. La valeur par défaut est « no ». Modifiez la valeur sur « yes » pour activer cet attribut. |
Comment Tableau renvoie les lignes depuis Google BigQuery
Tableau utilise deux approches pour renvoyer des lignes depuis BigQuery : l’approche par défaut sans spouling ou l’approche de table temporaire (spouling) :
Lors de la première tentative, les requêtes sont exécutées en utilisant la requête par défaut sans spouling, qui utilise le paramètre bq-fetch-rows.
Si l’ensemble de résultats est trop volumineux, l’API BigQuery renvoie une erreur et le connecteur Tableau BigQuery fait une nouvelle tentative de requête en enregistrant les résultats dans une table temporaire BigQuery. Le connecteur BigQuery lit ensuite la table temporaire, qui est une tâche de spouling utilisant le paramètre bq-large-fetch-rows.
Comment spécifier les attributs
Vous pouvez spécifier des attributs de l’une des deux manières suivantes : dans un fichier de personnalisation de source de données Tableau .tdc ou dans le code XML du classeur ou de la source de données.
Spécifier des attributs dans un fichier .tdc
Pour spécifier les attributs de personnalisation pendant une opération de publication de classeur ou de source de données, depuisTableau Desktop, procédez comme suit :
Créez un fichier XML contenant les attributs de personnalisation.
Enregistrez le fichier avec une extension
.tdc, par exempleBigQueryCustomization.tdc.Enregistrez le fichier dans le dossier
My Tableau Repository\Datasources.
Les attributs de personnalisation dans les fichiers .tdc sont lus et inclus par Tableau Desktop lors de la publication de la source de données ou du classeur dans Tableau Cloud ou Tableau Server.
Important : Tableau ne teste pas et ne prend pas en charge les fichiers TDC. Ces fichiers devraient être utilisés en tant qu’un outil pour explorer or résoudre occasionnellement les problèmes de votre connexion de données. La création et la gestion de fichiers TDC nécessitent une modification manuelle prudente et il n’y a aucune prise en charge du partage de ces fichiers.
Exemple d’un fichier .tdc avec les paramètres recommandés pour les extraits volumineux
<connection-customization class='bigquery' enabled='true' version='8.0' >
<vendor name='bigquery' />
<driver name='bigquery' />
<customizations>
<customization name='bq-fetch-tasks' value='10' />
<customization name='bq-large-fetch-rows' value='10000' />
</customizations>
</connection-customization>
Intégrer manuellement les attributs dans le code XML du fichier du classeur ou de la source de données
Vous pouvez intégrer manuellement les attributs de personnalisation dans la balise « connection » dans le fichier .twb du classeur ou le fichier .tds de la source de données. Les attributs de personnalisation BigQuery apparaissent en gras dans l’exemple suivant pour les rendre plus faciles à voir.
Exemple d’attributs intégrés manuellement
<connection CATALOG='publicdata' EXECCATALOG='some-project-123' REDIRECT_URI='some-url:2.0:oob' SCOPE='https://www.googleapis.com/auth/bigquery https://www.googleapis.com/auth/userinfo.profile https://www.googleapis.com/auth/userinfo.email' authentication='yes' bq-fetch-tasks='10' bq-large-fetch-rows='10000'bq_schema='samples' class='bigquery' connection-dialect='google-bql' connection-protocol='native-api' login_title='Sign in to Google BigQuery' odbc-connect-string-extras='' project='publicdata' schema='samples' server='googleapis.com/bigquery' server-oauth='' table='wikipedia' username=''>
Vérifier si votre classeur utilise SQL standard ou SQL hérité
En 2016, Google a mis à jour les API BigQuery de manière à prendre en charge SQL standard, en plus de prendre encore en charge BigQuery SQL (maintenant appelé SQL hérité). Depuis Tableau 10.1, le connecteur Google BigQuery a été mis à niveau de manière à prendre en charge SQL standard, en plus de SQL hérité. SQL standard permet aux utilisateurs du connecteur BigQuery d’utiliser des expressions de niveau de détail, d’obtenir une validation plus rapide des métadonnées et de sélectionner un projet de facturation avec la connexion.
Désormais, lorsque vous créez un classeur, Tableau prend en charge SQL standard par défaut. Tableau prend également en charge SQL hérité à l’aide de l’option Utiliser SQL hérité dans le volet Données. Par exemple, lorsque vous ouvrez un classeur qui a été créé à l’aide d’une version précédente de Tableau Desktop, et si votre classeur utilise SQL hérité, l’option Utiliser SQL hérité est sélectionnée.
Vous pouvez souhaiter configurer l’option Utiliser SQL hérité pour les raisons suivantes :
Vous avez un classeur existant que vous souhaitez mettre à jour pour utiliser SQL standard afin d’écrire des expressions de niveau de détail ou de tirer parti d’autres améliorations. Dans ce cas, assurez-vous que l’option Utiliser SQL hérité n’est pas sélectionnée.
Vous créez un classeur qui a besoin d’être connecté à une vue SQL hérité. Étant donné que vous ne pouvez pas mélanger SQL hérité et SQL standard, vous devez sélectionner la case à cocher Utiliser SQL hérité pour que le classeur fonctionne.
Dans Google BigQuery, les vues sont écrites en SQL standard ou SQL hérité. Vous pouvez lier les vues écrites en SQL standard à des vues écrites en SQL standard, ou des vues écrites en SQL hérité à des vues écrites en SQL hérité, et vous pouvez lier dans une table des vues écrites dans l’une ou l’autre des versions SQL. Par contre, vous ne pouvez pas lier des vues écrites en SQL standard et des vues écrites en SQL hérité dans un seul classeur. Lorsque vous liez des vues, vous devez définir la case à cocher Utiliser SQL hérité en fonction du type de SQL utilisé dans la vue à laquelle vous vous connectez.
Remarque : Tableau Desktop assure une prise en charge limitée des données imbriquées si vous utilisez SQL hérité ou SQL standard. Par exemple, si la table contient des données imbriquées et que vous utilisez SQL hérité ou SQL standard, dans le volet Source de données, l’option Actualiser maintenant ne fonctionnera pas.
Pour plus d’informations sur la migration de SQL hérité à SQL standard, consultez Migrating from legacy SQL(Le lien s’ouvre dans une nouvelle fenêtre) sur le site Web de Google Cloud Platform.
Utiliser BigQuery BI Engine pour analyser les données
Vous pouvez utiliser BigQuery BI Engine pour exécuter des services d’analyse rapides et à faible latence et des analyses interactives avec des rapports et des tableaux de bord soutenus par BigQuery. Pour plus d’informations, y compris des instructions sur l’intégration de BigQuery BI Engine à Tableau, consultez Analyser les données BigQuery à l’aide de BI Engine et Tableau dans la documentation de Google.
Résoudre les problèmes Google BigQuery
Connexions à plusieurs comptes
Lorsque vous utilisez la création Web ou la publication sur le Web, vous ne pouvez pas utiliser plusieurs comptes Google BigQuery dans le même classeur. Vous pouvez avoir plusieurs connexions de compte Google BigQuery dans Desktop.
Lors de la publication des flux, les informations d’identification que vous utilisez pour vous connecter à Google BigQuery à l’étape des données entrantes doivent correspondre aux informations d’identification définies dans l’onglet Paramètres de la page Paramètres de Mon compte pour Google BigQuery dans Tableau Server ou Tableau Cloud. Si vous sélectionnez des informations d’identification différentes ou aucune information d’identification dans votre paramètre d’authentification lors de la publication du flux, le flux échouera avec une erreur d’authentification jusqu’à ce que vous modifiiez la connexion pour le flux dans Tableau Server ou Tableau Cloud de manière à ce que ces informations correspondent.
Création Web avec Internet Explorer 11 et Edge
Dans Internet Explorer 11 et Edge, vous ne pouvez pas accéder à un serveur en utilisant une connexion non sécurisée (http). Utilisez une connexion sécurisée (https) ou passez à un autre navigateur.
Voir également
- Configurer des sources de données – Ajoutez des données supplémentaires à cette source de données ou préparez vos données avant de les analyser.
- Créer des graphiques et analyser des données – Lancez votre analyse de données.
- Configurer Oauth pour Google(Le lien s’ouvre dans une nouvelle fenêtre) - Configurer les connexions Oauth pour Tableau Server.
- Connexions OAuth(Le lien s’ouvre dans une nouvelle fenêtre) - Configuration des connexions OAuth pour Tableau Cloud.
- Google BigQuery et Tableau : meilleures pratiques(Le lien s’ouvre dans une nouvelle fenêtre) - Lisez le livre blanc Tableau (inscription ou authentification requise)