Extraire vos données
Un extrait de données est un sous-ensemble d’informations enregistré séparément de l’ensemble de données d’origine. Il répond à deux objectifs : améliorer les performances et utiliser les fonctionnalités de Tableau qui ne sont pas nécessairement disponibles ou prises en charge dans les données d’origine. En créant un extrait de données, vous réduisez efficacement le volume global de données en appliquant des filtres et en définissant d’autres limitations.
Une fois créé, un extrait de données peut être actualisé avec les données les plus récentes de la source d’origine. Lors du processus d’actualisation, vous pouvez effectuer une actualisation complète, qui remplacera tout le contenu existant de l’extrait, ou vous pouvez opter pour une actualisation incrémentielle de manière à ajouter uniquement les lignes qui sont nouvelles depuis la dernière actualisation.
Remarque : depuis la version 2024.1, Tableau a introduit une fonctionnalité permettant aux utilisateurs d’effectuer des actualisations incrémentielles sur les extraits à l’aide d’une colonne de clé non unique. Consultez la section Actualisation incrémentielle pour plus d’informations.
Avantages des extraits
Gestion d’ensembles de données volumineux : les extraits peuvent gérer des quantités massives de données, jusqu’à plusieurs milliards de lignes. Les utilisateurs peuvent ainsi travailler efficacement avec de vastes ensembles de données.
Performances améliorées : l’interaction avec les vues qui utilisent les sources de données d’un extrait génère de meilleures performances par rapport aux vues connectées directement aux données d’origine. Les extraits optimisent les performances des requêtes, ce qui accélère l’analyse et la visualisation des données.
Fonctionnalité améliorée : les extraits donnent accès à des fonctionnalités Tableau supplémentaires qui ne sont pas nécessairement disponibles ou prises en charge par la source de données d’origine.
Par exemple, les utilisateurs peuvent exploiter les extraits pour calculer le Total distinct, accédant ainsi à des calculs et des analyses plus avancés.
Accès aux données hors ligne (Tableau Desktop) : les extraits permettent un accès hors ligne aux données. Ainsi, même lorsque la source de données d’origine n’est pas disponible, les utilisateurs peuvent continuer d’enregistrer, de traiter et de gérer les données localement.
Créer un extrait
Plusieurs options sont disponibles dans votre workflow Tableau pour créer un extrait, mais seule l’approche principale est expliquée ci-dessous.
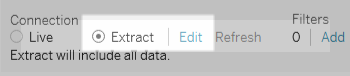
Connectez-vous aux données et configurez la source de données dans le volet Source de données, en haut à droite, sélectionnez Extrait, puis cliquez sur le lien Modifier pour ouvrir la boîte de dialogue Extraire des données.
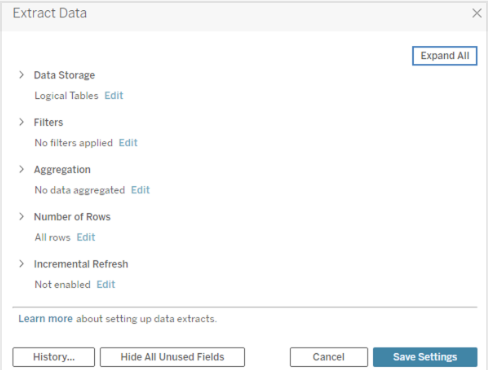
Sous Stockage des données, sélectionnez Tableaux logiques ou Tableaux physiques. Pour obtenir de l’aide pour cette étape, consultez la section Stockage de données.
Développez l’option Filtres pour définir un ou plusieurs filtres afin de limiter la quantité de données extraites en fonction de champs et de leurs valeurs.
Sélectionnez Agréger les données pour les dimensions visibles pour agréger les mesures à l’aide de leur agrégation par défaut.
(Facultatif) Sélectionnez Regrouper les dates dans un niveau de date spécifié tel que Année, Mois, etc.
Sélectionnez le nombre de lignes que vous souhaitez extraire. Vous pouvez extraire Toutes les lignes, un Échantillon ou les lignes N premiers.
Cochez la case Actualisation incrémentielle, puis indiquez la table à actualiser et la colonne de la base de données qui sera utilisée pour identifier les nouvelles lignes.
Une fois que vous avez terminé, choisissez Enregistrer les paramètres.
Sélectionnez l’onglet Feuille. La création de l’extrait démarre alors.
Ensuite, sélectionnez l’emplacement d’enregistrement de l’extrait.
Entrez un nom pour le fichier d’extrait.
Sélectionnez Enregistrer. Si la boîte de dialogue d’enregistrement ne s’affiche pas, consultez la section Résoudre les problèmes liés aux extraits ci-dessous.

Description des champs d’un extrait
Vous pouvez configurer de nombreux champs lors de la création d’un extrait. Cette section présente chaque champ en détail.
Stockage de données
Sous Stockage de données, vous pouvez sélectionner des tables logiques ou physiques. Les tables logiques stockent les données à l’aide d’une table d’extrait pour chaque table logique de la source de données. Les tables physiques, quant à elles, stockent les données à l’aide d’une table d’extrait pour chaque table physique dans la source de données.
Tables logiques
Si vous souhaitez limiter la quantité de données dans votre extrait et utiliser des propriétés d’extrait supplémentaires telles que des filtres, une agrégation ou la fonction N premiers, vous devez sélectionner Tables logiques.
Cette option fonctionne également bien lorsque vos données incluent des fonctions directes (RAWSQL).
Tableau utilise des tables logiques comme structure par défaut pour stocker les données d’extrait.
Si vous choisissez cette option et que votre extrait contient des jointures, ces dernières sont appliquées lors de la création de l’extrait.
Tables physiques
Si votre extrait est constitué de tables combinées avec des jointures d’égalité et répond aux conditions d’utilisation de l’option Tables physiques, vous devez sélectionner Tables physiques. Cette option exécute les jointures au moment de l’interrogation et peut potentiellement améliorer les performances et réduire la taille du fichier d’extrait.
Considérations sur l’utilisation de l’option Tables physiques. Pour que vous puissiez stocker votre extrait à l’aide de l’option Tables physiques, les données de votre extrait doivent remplir toutes les conditions énumérées ci-dessous.
Toutes les jointures entre les tables physiques sont des jointures d’égalité (=).
Les types de données des colonnes utilisées pour les relations ou les jointures sont identiques.
Aucune fonction directe (RAWSQL) n’est utilisée.
Aucune actualisation incrémentielle n’est configurée.
Aucun filtre d’extrait n’est configuré.
Aucune option N premiers ou d’échantillonnage n’est configurée.
Lorsque l’extrait est stocké sous la forme de tables physiques, vous ne pouvez pas lui ajouter des données.
Pour les tables logiques, vous ne pouvez pas ajouter des données à des extraits qui contiennent plus d’une table logique.
Conseils d’utilisation de l’option Tables physiques
Tableau vous recommande généralement d’utiliser l’option de stockage des données par défaut, Tables logiques, lorsque vous configurez et utilisez des extraits. Dans de nombreux cas, certaines des fonctionnalités dont vous avez besoin pour votre extrait, par exemple les filtres d’extrait, sont uniquement disponibles si vous utilisez l’option Tables logiques.
Option Tables physiques pour les extraits plus volumineux qu’attendu
Il est conseillé d’utiliser l’option Tables physiques avec parcimonie, dans des situations spécifiques, par exemple lorsque votre source de données répond aux conditions d’utilisation de l’option Tables physiques et que la taille de votre extrait est plus volumineuse qu’attendu. Pour déterminer si l’extrait est plus volumineux qu’il ne devrait, la somme des lignes dans l’extrait utilisant l’option Tables logiques doit être supérieure à la somme des lignes de toutes les tables combinées avant la création de l’extrait. Dans ce cas de figure, essayez plutôt d’utiliser l’option Tables physiques.
Suggestions alternatives de filtrage en cas d’utilisation de l’option Tables physiques Lorsque vous utilisez l’option Tables physiques, les autres options de réduction des données dans votre extrait, par exemple les filtres d’extrait, l’agrégation, N premiers et Échantillonnage, sont désactivées. Si vous avez besoin de réduire les données dans un extrait utilisant l’option Tables multiples, envisagez de filtrer les données avant qu’elles ne soient intégrées dans Tableau Desktop en utilisant l’une des suggestions suivantes :
Connectez-vous à vos données et définissez des filtres à l’aide de SQL personnalisé
Au lieu de vous connecter à une table de base de données, connectez-vous plutôt à vos données à l’aide de SQL personnalisé. Lorsque vous créez votre propre requête SQL personnalisée, assurez-vous qu’elle contient le niveau approprié de filtrage nécessaire pour réduire les données dans votre extrait. Pour plus d’informations sur la connexion à SQL personnalisé dans Tableau Desktop, voir Se connecter à une requête SQL personnalisée.
Définir une vue dans la base de données
Si vous disposez d’un accès en écriture à votre base de données, envisagez de définir une vue de base de données contenant simplement les données nécessaires pour votre extrait puis connectez-vous à la vue de base de données depuis Tableau Desktop.
Sécurité au niveau des lignes avec les extraits
Si vous souhaitez sécuriser les données d’extrait au niveau des lignes, il est recommandé d’utiliser l’option « Tables physiques » pour réaliser ce scénario. Pour plus d’informations sur la sécurité au niveau des lignes dans Tableau, consultez Restreindre l’accès au niveau des lignes de données.
Considérations générales sur les tables
Les options Tables logiques et Tables physiques affectent toutes deux uniquement la manière dont les données de votre extrait sont stockées. Elles n’affectent pas la manière dont les tables de votre extrait s’affichent dans le volet Source de données.
Supposons, par exemple, que votre extrait soit composé d’une table logique contenant trois tables physiques.
Si vous ouvrez directement le fichier d’extrait (.hyper) qui a été configuré pour utiliser l’option par défaut, Tables logiques, une seule table figure dans le volet Source de données.
Toutefois, si vous ouvrez l’extrait à l’aide du fichier de la source de données complète (.tdsx) ou le fichier de la source de données (.tdsx) avec son extrait correspondant (fichier .hyper), vous voyez les trois tables contenant l’extrait dans le volet Source de données.
Filtres
Utilisez les filtres pour définir un ou plusieurs filtres afin de limiter la quantité de données extraites en fonction de champs et de leurs valeurs.
Agrégation
L’agrégation vous permet de regrouper des mesures. Vous pouvez également sélectionner l’option Regrouper les dates dans un niveau de date spécifique, tel que Année, Mois, etc. Les exemples ci-dessous expliquent comment les données seront extraites pour chaque option d’agrégation choisie.
| Données d’origine | 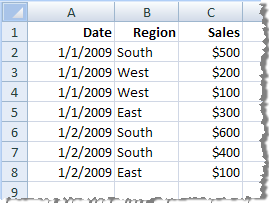 | Chaque enregistrement apparaît sur une ligne distincte. Vos données contiennent sept lignes. |
| Agréger les données pour les dimensions visibles (pas de regroupement) | 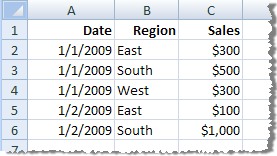 | Les enregistrements avec la même date et la même région ont été agrégés dans une seule ligne. Votre extrait contient cinq lignes. |
| Agréger les données pour les dimensions visibles (regrouper les dates dans Mois) | 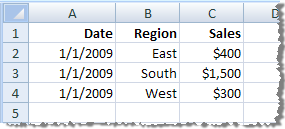 | Les dates ont été regroupées au niveau Mois et les enregistrements au sein de la même région ont été agrégés dans une seule ligne. Votre extrait contient trois lignes. |
Nombre de lignes
Vous pouvez extraire Toutes les lignes ou les lignes N premiers. Tableau applique d’abord les filtres et les agrégations, puis extrait le nombre de lignes des résultats filtrés et agrégés. Les options du nombre de lignes dépendent du type de source de données à partir duquel vous obtenez l’extrait. Il est possible que vous ne voyiez pas l’option Échantillonnage dans la boîte de dialogue Extraire les données, car certaines sources de données ne prennent pas en charge cette option.
Remarque(s) : tous les champs que vous masquez en premier dans la page Source de données ou dans l’onglet Feuille seront exclus de l’extrait. Cliquez sur le bouton Masquer tous les champs inutilisés pour supprimer les champs masqués de l’extrait.
Actualisation incrémentielle
La plupart des sources de données prennent en charge l’actualisation incrémentielle. Plutôt que d’actualiser la totalité de l’extrait, vous pouvez configurer l’actualisation de manière à ajouter uniquement les lignes nouvelles depuis la dernière extraction des données.
Par exemple, votre source de données peut être mise à jour tous les jours avec les nouvelles transactions de ventes. Plutôt que de recréer tous les jours la totalité de l’extrait, vous pouvez simplement ajouter les nouvelles transactions de chaque jour.
Conseils sur l’actualisation incrémentielle et les paramètres avancés
Cette section prodigue des conseils pour éviter les erreurs susceptibles de se produire lors de la configuration de ces fonctionnalités.
Actualisation incrémentielle :
Dans Nombre de lignes, vous devez sélectionner Toutes les lignes.
L’actualisation incrémentielle n’est pas disponible si vous activez l’agrégation.
Paramètres avancés :
Les paramètres avancés ne sont pas compatibles avec les filtres.
Conseils pour la création d’extraits
Enregistrez votre classeur pour conserver la connexion à l’extrait
Une fois l’extrait créé, le classeur commence à utiliser la version d’extrait de vos données. Par contre, la connexion à la version d’extrait de vos données n’est pas enregistrée tant que vous n’avez pas enregistré le classeur. Cela signifie que si vous fermez le classeur sans l’enregistrer, il se connectera à la source de données d’origine lors de sa prochaine ouverture.
Permuter entre des données échantillonnées et un extrait entier
Lorsque vous travaillez avec un extrait volumineux, il peut être utile de créer un échantillon plus petit des données. Vous pourrez ainsi configurer votre vue sans avoir à exécuter des requêtes longues à chaque fois que vous ajoutez un champ à votre analyse. Vous pouvez facilement basculer entre l’utilisation des exemples de données et la source de données complète en sélectionnant l’option appropriée dans le menu Données.
Ne vous connectez pas directement à l’extrait
Lorsque vous enregistrez des extraits sur votre ordinateur, vous pouvez vous y connecter directement à l’aide d’une nouvelle instance Tableau Desktop. Cette opération est toutefois déconseillée pour les raisons suivantes :
Les noms des tables peuvent être différents.
Les extraits utilisent une dénomination spéciale pour garantir que chaque table porte un nom unique, ce qui peut être difficile à comprendre.
Vous ne pouvez pas mettre à jour ni actualiser l’extrait.
Lorsque vous vous connectez directement à un extrait, Tableau le considère comme la source de données d’origine, plutôt que comme une copie. Cela signifie que vous ne pouvez pas le relier à votre source de données d’origine.
La structure et les relations entre les tables seront perdues.
La disposition et les connexions entre les tables sont stockées dans le fichier .tds, et non dans le fichier .hyper. Par conséquent, lorsque vous vous connectez directement au fichier .hyper, vous perdez ces informations. Si vous utilisez le stockage de tables logiques pour l’extrait, vous ne verrez aucune référence aux tables physiques d’origine.
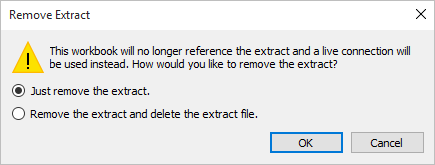
Supprimer l’extrait du classeur
Vous pouvez supprimer un extrait à tout moment en sélectionnant la source de données d’un extrait dans le menu Données puis en sélectionnant . Lorsque vous supprimez un extrait, vous pouvez choisir de Supprimer l’extrait du classeur uniquement ou de Supprimer le fichier d’extrait. Cette dernière option supprime l’extrait de votre disque dur.
Consulter l’historique de l’extrait (Desktop)
Pour voir la date de la dernière mise à jour de l’extrait et d’autres détails, sélectionnez une source de données dans le menu Données, puis sélectionnez .
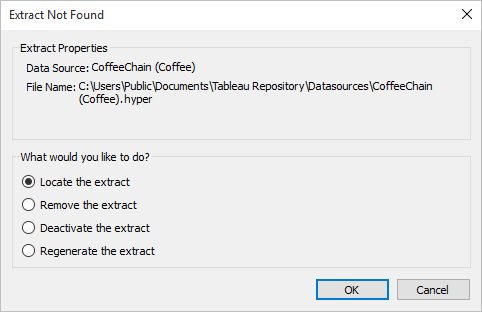
Si vous ouvrez un classeur enregistré avec un extrait et que Tableau ne peut pas localiser l’extrait, sélectionnez l’une des options suivantes dans la boîte de dialogue Extrait introuvable lorsque vous y êtes invité :
Localiser l’extrait : Sélectionnez cette option si l’extrait est présent, mais pas dans l’emplacement où Tableau l’a enregistré à l’origine. Cliquez sur OK pour ouvrir une boîte de dialogue Ouvrir un fichier où vous pouvez spécifier le nouvel emplacement pour le fichier d’extrait.
Supprimer l’extrait : Sélectionnez cette option si vous n’avez plus besoin de l’extrait. Cela équivaut à fermer la source de données. Toutes les feuilles de calcul ouvertes référençant la source de données sont supprimées.
Désactiver l’extrait : Utilisez la source de données d’origine à partir de laquelle l’extrait a été créé, au lieu de l’extrait.
Régénérer l’extrait : Recrée l’extrait. Tous les filtres et les autres personnalisations que vous avez spécifiés lors de la création initiale de l’extrait sont automatiquement appliqués.
Résoudre les problèmes liés aux extraits
La création d’un extrait prend un certain temps : selon la taille de votre ensemble de données, la création d’un extrait peut demander un certain temps. Toutefois, une fois que vous avez extrait les données et que vous les avez enregistrées sur votre ordinateur, les performances peuvent s’améliorer.
L’extrait n’est pas créé : si votre ensemble de données contient un très grand nombre de colonnes (de l’ordre du millier), Tableau risque de ne pas pouvoir créer l’extrait dans tous les cas. Si vous rencontrez des problèmes, vous pouvez envisager d’extraire moins de colonnes ou de restructurer les données sous-jacentes.
La boîte de dialogue Enregistrer ne s’affiche pas ou l’extrait n’est pas créé depuis un fichier.twbx : si vous suivez la procédure ci-dessus pour extraire des données à partir d’un classeur complet, la boîte de dialogue Enregistrer ne s’affiche pas. Lorsqu’un extrait est créé à partir d’un classeur complet (.twbx), le fichier d’extrait est automatiquement enregistré dans le package de fichiers associé au classeur complet. Pour accéder au fichier d’extrait que vous avez créé à partir du classeur complet, vous devez décompresser le classeur. Pour plus d’informations, consultez Classeurs complets.
Mise à jour des fonctionnalités des extraits
Actualisation incrémentielle
Depuis la version 2024.1, Tableau a introduit une fonctionnalité qui permet aux utilisateurs d’effectuer des actualisations incrémentielles sur les extraits à l’aide d’une colonne de clé non unique. Une nouvelle interface utilisateur prend en charge ces paramètres avancés.
Extraits sur le Web
À partir de la version 2020.4, les extraits sont disponibles en mode de création Web et sur le serveur de contenu. Vous n’avez désormais plus besoin d’utiliser Tableau Desktop pour extraire vos sources de données. Pour plus d’informations, consultez Créer des extraits sur le Web.
Extraits de table logiques et physiques
Avec l’introduction des tables logiques et des tables physiques dans le modèle de données Tableau avec la version 2020.2, les options de stockage d’extraits sont passées des tables uniques et tables multiples aux tables logiques et tables physiques. Ces options décrivent mieux la façon dont les extraits seront stockés. Pour plus d’informations, voir Extraire vos données.
Abandon du format .tde
Remarque : depuis mars 2023, les extraits utilisant le format .tde sont obsolètes dans Tableau Cloud, Tableau Public et Tableau Server (version 2023.1.0). Pour plus d’informations, consultez Mise à niveau d’extraits vers le format .hyper.
Depuis la version 10.5, lorsque vous créez un nouvel extrait, il utilise le format .hyper. Les extraits au format .hyper tirent parti du moteur de données amélioré, qui prend en charge des performances plus rapides d’analyse et de requête pour des ensembles de données plus volumineux.
De même, lorsqu’une tâche liée à un extrait est exécutée sur un extrait .tde à l’aide de la version 10.5, l’extrait est mis à niveau à un extrait .hyper. Après avoir été mis à niveau à un extrait .hyper, un extrait .tde ne peut pas revenir à l’extrait .tde. Pour plus d’informations, consultez Mise à niveau d’extraits vers le format .hyper.
Modifications apportées aux valeurs et aux repères dans la vue
Pour améliorer l’efficacité et l’évolutivité des extraits, les valeurs des extraits peuvent être calculées différemment dans les versions 10.5 et ultérieures par rapport aux versions 10.4 et antérieures. Les modifications apportées au mode de calcul des valeurs peuvent affecter la manière dont les repères de votre vue sont renseignés. Dans quelques rares cas, les modifications peuvent entraîner un changement de forme de la vue, ou la rendre vide. Ces modifications peuvent également s’appliquer aux sources de données suivantes : sources de données multiconnexion, sources de données utilisant des connexions en direct à des données basées sur des fichiers, sources de données se connectant à des données Google Sheets, sources de données basées sur le cloud, sources de données composées uniquement d’extraits, et sources de données WDC.
Pour avoir une idée des différences que vous pouvez constater dans votre vue si vous utilisez la version 2022.4, consultez les sections ci-dessous.
Format des valeurs de date et de date/heure
Dans la version 10.5 et versions ultérieures, les extraits sont soumis à des règles plus cohérentes et plus strictes quant au mode d’interprétation des chaînes de date via les fonctions DATE, DATETIME et DATEPARSE. Ceci affecte le mode d’analyse des dates, ou les formats et les modèles de date autorisés pour ces fonctions. Plus spécifiquement, les règles peuvent être généralisées comme suit :
- Les dates sont évaluées puis analysées par colonne, et non pas ligne.
- Les dates sont évaluées puis analysées en fonction des paramètres régionaux de création du classeur, et non des paramètres régionaux de l’ordinateur sur lequel la classeur est ouvert.
Ces nouvelles règles permettent d’améliorer l’efficacité des extraits et de produire des résultats conformes aux bases de données commerciales.
Toutefois, du fait de ces règles, en particulier dans les scénarios internationaux où le classeur est créé avec des paramètres régionaux différents de ceux dans lesquels le classeur est ouvert ou du serveur sur lequel le classeur est publié, vous pouvez voir que 1) les valeurs de date et de date/heure sont transformées en des valeurs de date et de date/heure différentes ou 2.)les valeurs de date et de date/heure deviennent Null. Lorsque vos valeurs de date et de date/heure sont transformées en des valeurs de date et de date/heure différentes ou deviennent Null, cela indique souvent qu’il y a des problèmes avec les données sous-jacentes.
Voici quelques raisons courantes pour lesquelles vous pouvez constater des changements de vos valeurs de date et de date/heure dans votre source de données d’extrait en utilisant la version 10.5 et ultérieure.
Raisons courantes des changements de valeurs de date et de date/heure | Causes courantes des valeurs null |
|---|---|
|
|
Scénario de date 1
Supposons que votre classeur ait été créé avec des paramètres régionaux anglais qui utilisent une source de données d’un extrait .tde. Le tableau ci-dessous montre une colonne de données de type chaîne contenue dans la source de données de l’extrait.
| 10/31/2018 |
| 31/10/2018 |
12/10/2018 |
Sur la base des paramètres régionaux anglais spécifiques, le format de la colonne de date était conçu pour suivre le format MJA (mois, jour, année). Les tableaux suivants montrent ce que Tableau affiche en fonction de ces paramètres régionaux lorsque la fonction DATE est utilisée pour convertir des valeurs de chaîne en valeurs de date.
| October 31, 2018 |
| October 31, 2018 |
| December 10, 2018 |
Si l’extrait est ouvert selon des paramètres régionaux allemands, voici ce que vous voyez :
| 31 Oktober 2018 |
| 31 Oktober 2018 |
| 12 Oktober 2018 |
Toutefois, une fois que l’extrait a été ouvert dans des paramètres régionaux allemands en utilisant les versions 10.5 et ultérieures, le format JMA (jour, mois, année) des paramètres régionaux allemands est appliqué de manière stricte et entraîne une valeur Null parce que l’une des valeurs ne suit pas le format JMA.
| Null |
| October 31, 2018 |
| October 12, 2018 |
Scénario de date 2
Supposons un autre classeur créé avec des paramètres régionaux anglais qui utilisent une source de données d’un extrait .tde. Le tableau ci-dessous montre une colonne de données de dates numériques contenue dans la source de données de l’extrait.
| 1112018 |
| 1212018 |
| 1312018 |
| 1412018 |
Sur la base des paramètres régionaux anglais spécifiques, le format de la colonne de date était conçu pour suivre le format MJA (mois, jour, année). Les tableaux suivants montrent ce que Tableau affiche en fonction de ces paramètres régionaux lorsque la fonction DATE est utilisée pour convertir des valeurs numériques en valeurs de date.
| 11/1/2018 |
| 12/1/2018 |
| Null |
| Null |
Scénario de date 3
Supposons que vous avez un classeur utilisant la source de données d’un extrait .tde. Le tableau ci-dessous montre une colonne de données de type chaîne contenue dans la source de données de l’extrait.
| 2018-10-31 |
| 2018-31-10 |
2018-12-10 |
| 2018-10-12 |
La date utilisant un format ISO, la colonne de date suit toujours le format YYYY-MM-DD. Les tableaux suivants montrent ce que Tableau affiche lorsque la fonction DATE est utilisée pour convertir des valeurs de chaîne en valeurs de date.
| October 10, 2018 |
| Null |
| December 10, 2018 |
| October 12, 2018 |
Remarque : dans les versions 10.4 (et versions antérieures), le format ISO et autres formats de date auraient pu produire des résultats différents selon les paramètres régionaux du lieu de création du classeur. Avec des paramètres régionaux anglais par exemple, les dates 2018-12-10 et 2018/12/10 produiraient toutes deux le 12 décembre 2018. Par contre, avec des paramètres régionaux allemands, le 2018-12-10 pourrait produire le 12 décembre 2018 et le 2018/12/10 pourrait produire le 12 octobre 2018.
Ordre de tri et casse des valeurs
Les extraits prennent en charge l’interclassement et peuvent donc trier de manière plus appropriée les chaînes qui ont des accents ou une casse différente.
Prenons par exemple une table de chaînes. En termes d’ordre de tri, cela signifie qu’une chaîne telle que Égypte est désormais classée correctement après Estonie et avant Fidji.
À propos des données Excel :
En matière de casse, cela signifie que la manière dont Tableau stocke les valeurs a changé entre la version 10.4 (et versions antérieures) et la version 10.5 (et versions ultérieures). Par contre les règles de tri et de comparaison des valeurs n’ont pas changé. Dans la version 10.4 (et versions antérieures), les chaînes telles que « Maison », « MAISON » et « maiSon » sont traitées de la même manière et stockées avec une seule valeur représentative. Dans la version 10.5 (et versions ultérieures), les mêmes chaînes sont considérées comme uniques et donc stockées en tant que valeurs individuelles. Pour plus d’informations, consultez Modifications du mode de calcul des valeurs.
Briser l’égalité dans les requêtes N principaux
Lorsqu’une requête N principaux dans votre extrait produit des valeurs en double pour une position spécifique dans un classement, la position qui brise l’égalité peut être différente en cas d’utilisation de la version 10.5 et versions ultérieures. Par exemple, supposons que vous créez un filtre 3 principaux. Les positions 3, 4 et 5 ont les mêmes valeurs. Si vous utilisez la version 10.4 et versions antérieures, le filtre Principal peut retourner les positions 1, 2 et 3. Toutefois, si vous utilisez la version 10.5 et versions ultérieures, le filtre principal peut renvoyer les positions 1, 2 et 5.
Précision des valeurs à virgule flottante
Les extraits sont plus aptes à tirer parti des ressources matérielles disponibles sur un ordinateur et donc à effectuer des opérations mathématiques de manière hautement parallèle. Pour cette raison, les nombres réels peuvent être agrégés par des extraits .hyper dans un ordre différent. Lorsque les nombres sont agrégés dans un ordre différent, vous pouvez voir des valeurs différentes dans votre vue après la virgule décimale à chaque fois que l’agrégation est calculée. La raison est que les additions et les multiplications à virgule flottante ne sont pas nécessairement associatives. Cela signifie que (a + b) + c n’est pas nécessairement identique à a + (b + c). De plus, les nombres réels peuvent être agrégés dans un ordre différent parce que la multiplication à virgule flottante n’est pas nécessairement distributive. Cela signifie que (a x b) x c n’est pas nécessairement identique à a x b x c. Ce type de comportement d’arrondi à virgule flottante dans les extraits .hyper ressemble au comportement d’arrondi à virgule flottante dans les bases de données commerciales.
Par exemple, supposons que votre classeur contienne un filtre de curseur sur un champ agrégé comportant des valeurs à virgules flottantes. Du fait que la précision des valeurs à virgule flottante a changé, le filtre peut désormais exclure un repère qui définit la limite supérieure ou inférieure de la plage de filtres. L’absence de ces nombres peut générer une vue vide. Pour résoudre ce problème, déplacez le curseur sur le filtre ou retirez ou ajoutez à nouveau le filtre.
Précision des agrégations
Les extraits optimisent les ensembles de données volumineux en tirant parti des ressources matérielles disponibles sur un ordinateur et sont donc capables de calculer des agrégations de manière hautement parallèle. Pour cette raison, les agrégations effectuées par des extraits .hyper peuvent s’apparenter aux résultats de bases de données commerciales davantage que les résultats fournis par des logiciels spécialisés dans les calculs statistiques. Si vous utilisez un ensemble de données de petite dimension ou que vous avez besoin d’un niveau supérieur de précision, vous pouvez envisager de réaliser les agrégations via des lignes de référence, des statistiques de fiches Résumé, ou des fonctions de calcul de table telles que la variance, l’écart-type, la corrélation ou la covariance.
À propos de l’option Exécuter les calculs maintenant pour les extraits
Si l’option Exécuter les calculs maintenant a été utilisée dans un extrait .tde à l’aide d’une version plus ancienne de Tableau Desktop, certains champs calculés ont été matérialisés et donc calculés par avance et stockés dans l’extrait. Si vous mettez à niveau l’extrait depuis un extrait .tde vers un extrait .hyper, les calculs précédemment matérialisés dans votre extrait ne sont pas inclus. Vous devez utiliser l’option Exécuter les calculs maintenant à nouveau pour que les calculs matérialisés fassent bien partie de l’extrait après sa mise à niveau. Pour plus d’informations, consultez Matérialiser les calculs dans vos extraits.
Nouvelle interface Extract API
Vous pouvez désormais utiliser l’interface de programmation d’applications Extract API 2.0 pour créer des extraits .hyper. Pour les tâches que vous avez précédemment exécutées à l’aide du SDK de Tableau, par exemple la publication d’extraits, vous pouvez utiliser l’API REST de Tableau Server ou la bibliothèque du client Tableau Server (Python). Pour les tâches d’actualisation, vous pouvez également utiliser l’API REST de Tableau Server. Pour plus d’informations, consultez API Tableau Hyper.