JSON 파일
이 문서에서는 Tableau를 로컬 JSON 파일에 연결하고 데이터 원본을 설정하는 방법에 대해 설명합니다.
연결한 후 데이터 원본 설정
Tableau를 시작하고 연결에서 JSON 파일을 선택합니다. 그런 후 다음을 수행합니다.
연결하려는 파일을 선택하고 열기를 선택합니다.
스키마 수준 선택 대화 상자에서 Tableau에서 보고 분석하려는 스키마 수준을 선택한 다음 확인을 선택합니다. 자세한 내용은 스키마 수준 선택을 참조하십시오.
데이터 원본 페이지에서 다음을 수행합니다.
(선택 사항) 페이지 상단에서 기본 데이터 원본 이름을 선택한 다음 Tableau에서 사용할 고유한 데이터 원본 이름을 입력합니다. 예를 들어 데이터 원본을 사용하는 다른 사용자가 어떤 데이터 원본에 연결해야 하는지를 쉽게 알 수 있는 데이터 원본 명명 규칙을 사용하십시오.
시트 탭을 선택하여 분석을 시작합니다.
JSON 파일 데이터 원본 예
다음은 Windows 컴퓨터에서 Tableau Desktop을 사용하는 JSON 파일 데이터 원본의 예입니다.
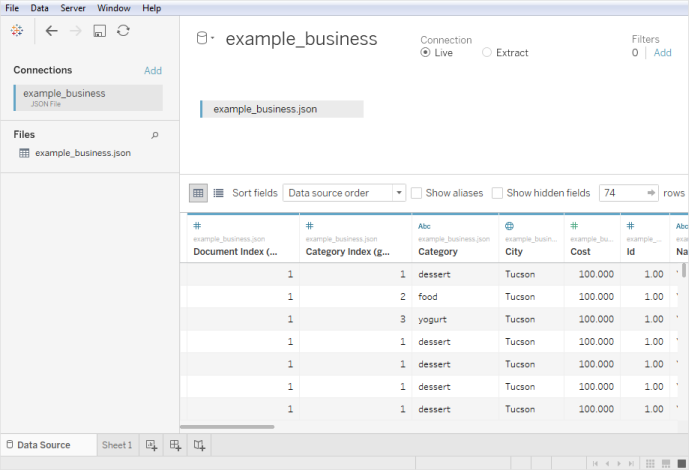
스키마 수준 선택
Tableau를 JSON 파일에 연결할 경우 Tableau는 JSON 파일에서 첫 10,000개 행의 데이터를 검사하여 스키마를 유추합니다. Tableau는 이 유추된 스키마를 사용하여 데이터를 평활화합니다. JSON 파일 스키마 수준은 스키마 수준 선택 대화 상자에 나열됩니다. Tableau Desktop에서 JSON 파일에 10,000개 이상의 행이 있는 경우 "전체 문서 검사" 옵션을 사용하여 스키마를 만들 수 있습니다.
참고: "전체 문서 검사" 옵션은 행이 10,000개가 넘는 JSON 파일에 대해서만 표시됩니다. 웹에서는 이 옵션을 사용할 수 없습니다.
대화 상자에서 선택한 스키마 수준에 따라 Tableau에서 보고 분석할 수 있는 차원 및 측정값이 결정됩니다. 또한 어떤 데이터가 게시되는지 결정합니다.
참고: 통합 문서를 웹에 게시하면 어떤 스키마 업데이트도 비주얼리제이션의 웹 버전에서 사용할 수 없으며, 나중에 비주얼리제이션을 새로 고치면 오류가 발생할 수 있습니다.
하위 스키마 수준을 선택하면 상위 수준도 선택됩니다.
| JSON 파일 예: | JSON 파일이 생성하는 스키마 수준: |
 | 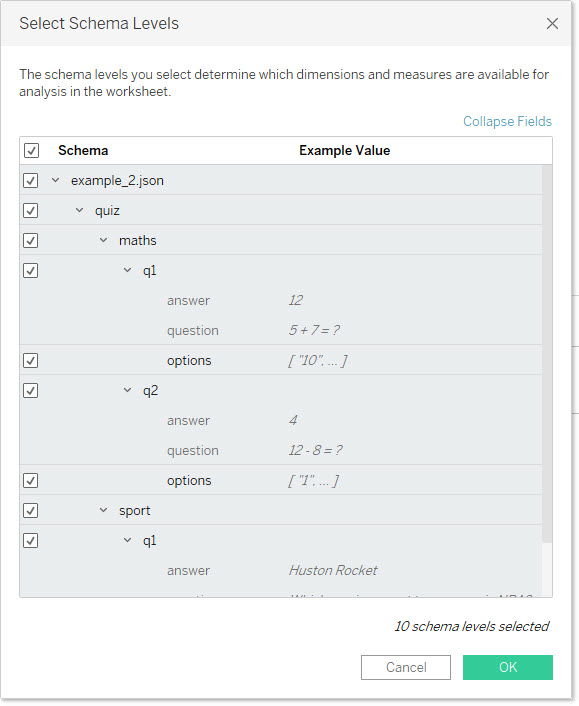 |
새 필드 감지
유추된 스키마를 만들기 위해 검사하지 않은 행에 더 많은 필드가 존재하는 경우가 있습니다. 필요한 필드가 스키마에서 누락된 경우 다음 중 하나 선택하여 수행할 수 있습니다.
전체 JSON 문서를 검사합니다. 검사가 완료되는 데 오랜 시간이 걸릴 수 있습니다.
나열된 스키마에서 스키마 수준을 선택한 다음 확인을 선택합니다. Tableau가 전체 문서를 읽고 더 많은 필드를 찾은 경우 스키마 수준 선택 대화 상자에 나열됩니다.
예를 들어 추출을 새로 고치는 동안이나 스키마 수준을 선택한 후 Tableau가 추출을 만들 때와 같이, Tableau가 사용할 수 있는 새 필드를 감지할 때마다 파일 이름 옆에 있는 정보 아이콘이나 스키마 수준 선택 대화 상자의 알림에 추가 필드를 찾았다는 표시가 나타납니다.
스키마 수준 변경
선택한 스키마 수준을 변경하려면 데이터 원본 페이지로 이동하고 데이터 > [JSON 파일 이름] > 스키마 수준 선택을 선택합니다. 또는 캔버스에서 파일 이름을 마우스오버하고 드롭다운 메뉴 > 스키마 수준 선택을 선택합니다.
JSON 파일 유니온
JSON 데이터를 유니온할 수 있습니다. JSON 파일을 유니온하려면 확장명이 .json, .txt 또는 .log여야 합니다. 유니온에 대한 자세한 내용은 데이터 유니온을 참조하십시오.
JSON 파일을 유니온할 경우 유니온에 포함된 모든 파일의 첫 10,000개 행에서 스키마가 유추됩니다.
파일을 유니온한 후 스키마 수준을 변경할 수 있습니다. 자세한 내용은 스키마 수준 변경을 참조하십시오.
계층적 JSON 파일에 대해 차원 폴더가 구성되는 방법
시트 탭을 선택한 후 JSON 파일의 선택한 스키마 수준이 데이터 패널의 차원 아래에 표시됩니다. 각 폴더는 선택한 스키마 수준에 해당하며, 해당 스키마 수준과 연결된 특성이 폴더의 하위로 나열됩니다.
예를 들어 다음 이미지에서 Address는 Businesses 폴더 스키마 수준 아래에 있는 차원입니다. Categories도 스키마 수준이지만 데이터 계층이 아니라 값 목록이기 때문에 고유한 폴더가 필요하지 않습니다. 그 대신 상위 폴더 아래에 그룹화됩니다. 스키마 수준 선택 대화 상자의 스키마 수준은 데이터 패널의 폴더 구조에 직접 매핑되지 않습니다. 데이터 패널의 폴더는 개체별로 그룹화되기 때문에 필드를 쉽게 탐색할 수 있으며 필드가 제공되는 위치에 대한 컨텍스트도 사용할 수 있습니다.
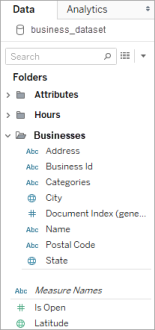
각 문서에 대해 고유한 인덱스가 생성되고 평활화된 데이터 표현으로 저장됩니다. 스키마의 각 수준에 대한 인덱스도 생성됩니다.
예를 들어 위 이미지에서 문서 인덱스(생성됨) 항목과 함께, Attribute 및 Hours 스키마 수준 모두 생성된 인덱스가 있습니다.
계층적 JSON 파일에서 측정값이 계산되는 이유
계층적 JSON 파일이 평활화될 때 데이터가 중복될 수 있습니다. 측정값과 해당 스키마 수준을 일관되게 유지하기 위해 Tableau에서는 스키마 수준에서 데이터를 정확하게 표현하는 LOD(세부 수준) 계산을 만듭니다. 원래 측정값은 원본 측정값 폴더에 배치되며, 이를 사용할 수 있지만 계산된 측정값을 사용하는 것이 좋습니다.
데이터 패널에서 계산된 측정값에는 <측정값 이름> 수(<상위 이름>당) 레이블이 지정됩니다.
![]()
측정값에 대한 LOD 계산을 보려면 다음 단계를 수행합니다.
측정값을 선택합니다.
드롭다운 화살표를 선택하고 편집을 선택합니다.
다음 예제에서는 Revenue per Document에 대한 LOD 계산을 보여 줍니다. 이 수식은 각 문서 인덱스 값에 대한 최대 수익을 선택합니다.
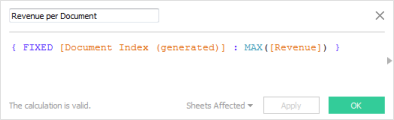
LOD 계산을 사용하므로 여러 스키마 수준을 선택할 수 있고 측정값이 초과 카운트되지 않는다고 확신할 수 있습니다.
JSON 데이터 작업을 위한 팁
Tableau에서 JSON 데이터로 작업할 때 다음과 같은 팁이 도움이 될 수 있습니다.
중첩된 배열에 대한 10x10 제한을 초과하지 마십시오.
중첩이 심한 배열은 많은 행을 생성합니다. 예를 들어 10x10 중첩 배열은 100억개 행을 생성합니다. Tableau가 메모리에 로드할 수 있는 행 수가 초과되면 오류가 표시됩니다. 이 경우 스키마 수준 선택 대화 상자를 사용하여 선택된 스키마 수준의 수를 줄이십시오.
100개 수준 이상의 JSON 개체가 포함된 데이터 원본은 로드에 긴 시간이 걸릴 수 있습니다.
많은 수준은 많은 열을 생성하기 때문에 처리에 오랜 시간이 걸릴 수 있습니다. 예를 들어 100개 수준인 경우 데이터 로드에 2분 이상이 걸릴 수 있습니다. 최상의 방법은 스키마 수준의 수를 분석에 필요한 최소한의 수준으로 줄이는 것입니다.
단일 JSON 개체가 128MB를 초과할 수 없습니다.
단일 개체의 최상위 배열이 128MB를 초과하면 JSON 개체가 한 줄에 하나씩 정의되어 있는 파일로 변환해야 합니다.
피벗 옵션이 지원되지 않습니다.
TTDE 및 HHYPER 파일 정보
컴퓨터의 디렉터리를 탐색할 때 .ttde 또는 .hhyper 파일에 주의해야 합니다. 데이터에 연결하는 Tableau 데이터 원본을 만드는 경우 Tableau가 .ttde 또는 .hhyper 파일을 만듭니다. 섀도 추출이라고도 알려진 이 파일을 사용하여 Tableau Desktop에서 데이터 원본 로드 속도를 향상시킬 수 있습니다. 섀도 추출은 표준 Tableau 추출과 유사하게 기초 데이터 및 기타 정보를 포함하지만 다른 형식으로 저장되며 데이터 복구에 사용할 수 없습니다.
참고 항목
- 데이터 원본 설정 – 이 데이터 원본에 더 많은 데이터를 추가하거나 데이터를 분석할 수 있도록 준비합니다.
- 차트 작성 및 데이터 분석 – 데이터 분석을 시작합니다.