문자열 함수
이 문서에서는 Tableau의 문자열 함수와 관련 사용법을 소개합니다. 또한 예제를 사용하여 문자열 계산을 만드는 방법을 보여 줍니다.
문자열 함수를 사용하는 이유
문자열 함수를 사용하여 문자열 데이터(예: 텍스트로 구성된 데이터)를 조작할 수 있습니다. Tableau는 문자열을 비교할 때 현재 ICU(International Components for Unicode) 라이브러리를 사용합니다. 문자열 정렬 및 비교 방법은 언어와 로캘에 기준을 둡니다. ICU는 언어 지원을 개선하기 위해 지속적으로 업데이트되므로 비주얼리제이션이 변경될 수 있습니다.
예를 들어 고객의 이름 및 성을 모두 포함하는 필드가 있다고 가정합니다. 한 멤버는 Jane Johnson입니다. 이 경우 문자열 함수를 사용하여 모든 고객의 성을 가져와 새 필드에 저장할 수 있습니다.
계산은 다음과 비슷한 모양입니다.
SPLIT([Customer Name], ' ', 2)
즉, SPLIT('Jane Johnson' , ' ', 2) = 'Johnson'입니다.
Tableau에서 사용할 수 있는 문자열 함수
ASCII
| 구문 | ASCII(string) |
| 출력 | 숫자 |
| 정의 | <string>에서 첫 번째 문자의 ASCII 코드를 반환합니다. |
| 예 | ASCII('A') = 65 |
| 참고 | CHAR 함수의 반대입니다. |
CHAR
| 구문 | CHAR(number) |
| 출력 | 문자열 |
| 정의 | ASCII 코드 <number>로 인코딩되는 문자를 반환합니다. |
| 예 | CHAR(65) = 'A' |
| 참고 | ASCII 함수의 반대입니다. |
CONTAINS
| 구문 | CONTAINS(string, substring) |
| 출력 | 부울 |
| 정의 | 주어진 문자열에 지정한 부분 문자열이 포함되어 있으면 true를 반환합니다. |
| 예 | CONTAINS("Calculation", "alcu") = true |
| 참고 | 추가 함수 설명서(링크가 새 창에서 열림)에서 논리 함수(링크가 새 창에서 열림) IN과 지원되는 RegEx도 참조하십시오. |
ENDSWITH
| 구문 | ENDSWITH(string, substring) |
| 출력 | 부울 |
| 정의 | 주어진 문자열이 지정한 부분 문자열로 끝나면 true를 반환합니다. 후행 공백은 무시됩니다. |
| 예 | ENDSWITH("Tableau", "leau") = true |
| 참고 | 추가 함수 설명서(링크가 새 창에서 열림)에서 지원되는 RegEx도 참조하십시오. |
FIND
| 구문 | FIND(string, substring, [start]) |
| 출력 | 숫자 |
| 정의 | 문자열에서 부분 문자열의 인덱스 위치를 반환하거나, 부분 문자열을 찾을 수 없으면 0을 반환합니다. 문자열에서 첫 번째 문자가 위치 1입니다. 선택적 숫자 인수 |
| 예 | FIND("Calculation", "alcu") = 2FIND("Calculation", "Computer") = 0FIND("Calculation", "a", 3) = 7FIND("Calculation", "a", 2) = 2FIND("Calculation", "a", 8) = 0 |
| 참고 | 추가 함수 설명서(링크가 새 창에서 열림)에서 지원되는 RegEx도 참조하십시오. |
FINDNTH
| 구문 | FINDNTH(string, substring, occurrence) |
| 출력 | 숫자 |
| 정의 | 문자열 내 부분 문자열에서 n번째 일치 항목의 위치를 반환합니다. 여기서, n은 occurrence 인수로 정의됩니다. |
| 예 | FINDNTH("Calculation", "a", 2) = 7 |
| 참고 |
추가 함수 설명서(링크가 새 창에서 열림)에서 지원되는 RegEx도 참조하십시오. |
LEFT
| 구문 | LEFT(string, number) |
| 출력 | 문자열 |
| 정의 | 문자열의 가장 왼쪽에서 <number>개 문자를 반환합니다. |
| 예 | LEFT("Matador", 4) = "Mata" |
| 참고 | 또한 MID 및 RIGHT을 참조하십시오. |
LEN
| 구문 | LEN(string) |
| 출력 | 숫자 |
| 정의 | 문자열의 길이를 반환합니다. |
| 예 | LEN("Matador") = 7 |
| 참고 | 공간 함수(링크가 새 창에서 열림) LENGTH와 혼동하지 마십시오. |
LOWER
| 구문 | LOWER(string) |
| 출력 | 문자열 |
| 정의 | 제공된 <string>을 모두 소문자로 반환합니다. |
| 예 | LOWER("ProductVersion") = "productversion" |
| 참고 | 또한 UPPER 및 PROPER을 참조하십시오. |
LTRIM
| 구문 | LTRIM(string) |
| 출력 | 문자열 |
| 정의 | 모든 선행 공백을 제거하여 제공된 <string>을 반환합니다. |
| 예 | LTRIM(" Matador ") = "Matador " |
| 참고 | RTRIM도 참조하십시오. |
MAX
| 구문 | MAX(expression) 또는 MAX(expr1, expr2) |
| 출력 | 인수와 동일한 데이터 유형이거나, 인수의 일부가 null인 경우 NULL 값이 출력됩니다. |
| 정의 | 두 인수의 최대값을 반환합니다(두 인수가 동일한 데이터 유형이어야 함).
|
| 예 | MAX(4,7) = 7 |
| 참고 | 문자열의 경우
데이터베이스 데이터 원본의 경우 날짜의 경우 날짜의 경우 집계 형식
비교 형식
|
MID
| 구문 | (MID(string, start, [length]) |
| 출력 | 문자열 |
| 정의 | 지정된 선택적 숫자 인수 |
| 예 | MID("Calculation", 2) = "alculation"MID("Calculation", 2, 5) ="alcul" |
| 참고 | 추가 함수 설명서(링크가 새 창에서 열림)에서 지원되는 RegEx도 참조하십시오. |
MIN
| 구문 | MIN(expression) 또는 MIN(expr1, expr2) |
| 출력 | 인수와 동일한 데이터 유형이거나, 인수의 일부가 null인 경우 NULL 값이 출력됩니다. |
| 정의 | 두 인수의 최소값을 반환합니다(두 인수가 동일한 데이터 유형이어야 함).
|
| 예 | MIN(4,7) = 4 |
| 참고 | 문자열의 경우
데이터베이스 데이터 원본의 경우 날짜의 경우 날짜의 경우 집계 형식
비교 형식
|
PROPER
| 구문 | PROPER(string) |
| 출력 | 문자열 |
| 정의 | 각 단어의 첫 글자를 대문자로 표시하고 나머지 글자를 소문자로 표시하도록 제공된 |
| 예 | PROPER("PRODUCT name") = "Product Name"PROPER("darcy-mae") = "Darcy-Mae" |
| 참고 | 문장 부호와 같은 영숫자 외 문자와 공백은 구분 기호로 처리됩니다. |
| 데이터베이스 제한 사항 | PROPER는 일부 플랫 파일과 추출에만 사용할 수 있습니다. PROPER를 지원하지 않는 데이터 원본에서 PROPER를 사용해야 하는 경우 추출을 사용하는 것이 좋습니다. |
REPLACE
| 구문 | REPLACE(string, substring, replacement |
| 출력 | 문자열 |
| 정의 | <string>에서 <substring>을 검색하여 <replacement>로 바꿉니다. <substring>이 없으면 문자열이 변경되지 않습니다. |
| 예 | REPLACE("Version 3.8", "3.8", "4x") = "Version 4x" |
| 참고 | 추가 함수 설명서(링크가 새 창에서 열림)에서 REGEXP_REPLACE도 참조하십시오. |
RIGHT
| 구문 | RIGHT(string, number) |
| 출력 | 문자열 |
| 정의 | 문자열의 가장 오른쪽에서 <number>개 문자를 반환합니다. |
| 예 | RIGHT("Calculation", 4) = "tion" |
| 참고 | 또한 LEFT 및 MID을 참조하십시오. |
RTRIM
| 구문 | RTRIM(string) |
| 출력 | 문자열 |
| 정의 | 모든 후행 공백을 제거하여 제공된 <string>을 반환합니다. |
| 예 | RTRIM(" Calculation ") = " Calculation" |
| 참고 | 또한 LTRIM 및 TRIM을 참조하십시오. |
SPACE
| 구문 | SPACE(number) |
| 출력 | 문자열(특히 공백) |
| 정의 | 지정된 숫자만큼 반복된 공백으로 구성된 문자열을 반환합니다. |
| 예 | SPACE(2) = " " |
SPLIT
| 구문 | SPLIT(string, delimiter, token number) |
| 출력 | 문자열 |
| 정의 | 구분 기호 문자를 사용하여 문자열을 토큰 시퀀스로 분할하는 방식으로 문자열에서 부분 문자열을 반환합니다. |
| 예 | SPLIT ("a-b-c-d", "-", 2) = "b"SPLIT ("a|b|c|d", "|", -2) = "c" |
| 참고 | 문자열은 구분 기호와 토큰이 교대로 나타나는 형식으로 해석됩니다. 따라서 구분 문자가 '
추가 함수 설명서(링크가 새 창에서 열림)에서 지원되는 REGEX도 참조하십시오. |
| 데이터베이스 제한 사항 | 분할 및 사용자 지정 분할 명령을 사용할 수 있는 데이터 원본 유형은 Tableau 데이터 추출, Microsoft Excel, 텍스트 파일, PDF 파일, Salesforce, OData, Microsoft Azure Market Place, Google 애널리틱스, Vertica, Oracle, MySQL, PostgreSQL, Teradata, Amazon Redshift, Aster Data, Google Big Query, Cloudera Hadoop Hive, Hortonworks Hive 및 Microsoft SQL Server입니다. 일부 데이터 원본은 문자열 분할에 제한이 있습니다. 이 항목 뒷부분의 SPLIT 함수 제한 사항을 참조하십시오. |
STARTSWITH
| 구문 | STARTSWITH(string, substring) |
| 출력 | 부울 |
| 정의 | string이 substring으로 시작하면 true를 반환합니다. 선행 공백은 무시됩니다. |
| 예 | STARTSWITH("Matador, "Ma") = TRUE |
| 참고 | 추가 함수 설명서(링크가 새 창에서 열림)에서 CONTAINS와 지원되는 REGEX도 참조하십시오. |
TRIM
| 구문 | TRIM(string) |
| 출력 | 문자열 |
| 정의 | 선행 공백과 후행 공백이 모두 제거된 <string>을 반환합니다. |
| 예 | TRIM(" Calculation ") = "Calculation" |
| 참고 | 또한 LTRIM 및 RTRIM을 참조하십시오. |
UPPER
| 구문 | UPPER(string) |
| 출력 | 문자열 |
| 정의 | 제공된 <string>을 모두 대문자로 반환합니다. |
| 예 | UPPER("Calculation") = "CALCULATION" |
| 참고 | 또한 PROPER 및 LOWER을 참조하십시오. |
문자열 계산 만들기
아래의 단계를 수행하여 문자열 계산을 만드는 방법을 배워 보십시오.
Tableau Desktop에서 Tableau와 함께 제공된 샘플 – 슈퍼스토어라는 저장된 데이터 원본에 연결합니다.
워크시트로 이동합니다.
데이터 패널의 차원에서 Order ID를 행 선반에 끌어 놓습니다.
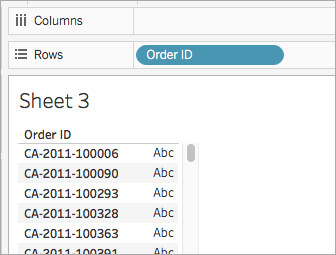
모든 Order ID에는 국가(예: CA 및 US), 연도(2011) 및 주문 번호(100006)에 대한 값이 포함됩니다. 이 예제에서는 필드에서 주문 번호만 가져오는 계산을 만듭니다.
분석 > 계산된 필드 만들기를 선택합니다.
계산 에디터가 열리면 다음을 수행합니다.
계산된 필드의 이름을 Order ID Numbers로 지정합니다.
다음 수식을 입력합니다.
RIGHT([Order ID], 6)이 수식은 문자열의 오른쪽부터 지정된 자릿수(6)를 가져와서 새 필드에 저장합니다.
즉,
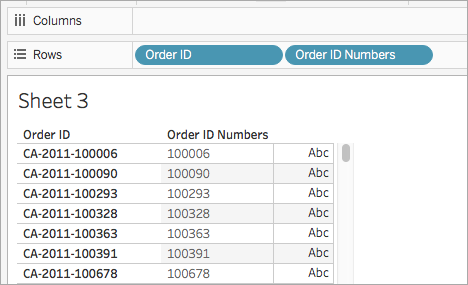
RIGHT('CA-2011-100006' , 6)= '100006'입니다.작업을 마쳤으면 확인을 클릭합니다.
새 계산된 필드가 데이터 패널의 차원 아래에 나타납니다. 다른 필드와 마찬가지로, 하나 이상의 비주얼리제이션에서 이 필드를 사용할 수 있습니다.
데이터 패널에서 Order ID Numbers를 행 선반에 끌어 놓습니다. 필드를 Order ID 오른쪽에 배치합니다.
이제 필드가 어떻게 달라지는지 확인합니다.
데이터 원본별 SPLIT 제한 사항
일부 데이터 원본은 문자열 분할에 제한이 있습니다. 다음 표에서는 음수 토큰 번호(오른쪽부터 분할)를 지원하는 데이터 원본과 데이터 원본에 따라 허용되는 분할 수에 제한이 있는지 여부를 보여 줍니다.
이러한 데이터 원본에서는 음수 토큰 번호가 지정되어 다른 데이터 원본에서는 유효한 SPLIT 함수가 다음 오류를 반환합니다. "오른쪽부터 분할하는 기능은 데이터 원본에서 지원되지 않습니다."
| 데이터 원본 | 왼쪽/오른쪽 제약 조건 | 최대 분할 수 | 버전 제한 |
| Tableau 데이터 추출 | 둘 다 | 제한 없음 | |
| Microsoft Excel | 둘 다 | 제한 없음 | |
| 텍스트 파일 | 둘 다 | 제한 없음 | |
| Salesforce | 둘 다 | 제한 없음 | |
| OData | 둘 다 | 제한 없음 | |
| Google 애널리틱스 | 둘 다 | 제한 없음 | |
| Tableau 데이터 서버 | 둘 다 | 제한 없음 | 버전 9.0에서 지원됩니다. |
| Vertica | 왼쪽만 | 10 | |
| Oracle | 왼쪽만 | 10 | |
| MySQL | 둘 다 | 10 | |
| PostgreSQL | 9.0 이전 버전에서는 왼쪽만, 9.0 이상 버전에서는 둘 다 | 10 | |
| Teradata | 왼쪽만 | 10 | 버전 14 이상 |
| Amazon Redshift | 왼쪽만 | 10 | |
| Aster Database | 왼쪽만 | 10 | |
| Google BigQuery | 왼쪽만 | 10 | |
| Hortonworks Hadoop Hive | 왼쪽만 | 10 | |
| Cloudera Hadoop | 왼쪽만 | 10 | Impala는 버전 2.3.0부터 지원됩니다. |
| Microsoft SQL Server | 둘 다 | 10 | 2008 이상 |