Como funcionam as funções de modelagem preditiva no Tableau
Você já pode adicionar linhas de tendência e previsões a uma visualização, mas agora pode ir além disso, usando a eficiência de um mecanismo estatístico para criar um modelo que entenda como os dados são distribuídos em uma linha de tendências ou linha de melhor ajuste. Anteriormente, os usuários precisavam integrar o Tableau com R e Python para realizar cálculos estatísticos avançados e visualizá-los no Tableau. Agora, você pode usar as funções de modelagem preditiva para fazer previsões dos dados, incluindo-os em um cálculo de tabela. Para obter mais informações sobre os cálculos de tabela, consulte Transformar valores com cálculos de tabela.
Com essas funções de modelagem preditiva, você pode selecionar destinos e preditores atualizando as variáveis e visualizando vários modelos com diferentes combinações de preditores. Os dados podem ser filtrados, agregados e transformados em qualquer nível de detalhe e, o modelo – e, portanto, a previsão – será recalculado automaticamente para corresponder aos dados.
Para obter um exemplo detalhado, que mostra como criar cálculos de previsão usando essas funções, consulte Exemplo - Explore a expectativa de vida das mulheres com as funções de modelagem preditiva.
Funções de modelagem preditiva disponíveis no Tableau
MODEL_PERCENTILE
| Sintaxe | MODEL_PERCENTILE(
|
| Definição | Retorna a probabilidade (entre 0 e 1) do valor esperado ser menor ou igual à marca observada, definida pela expressão-alvo e outros preditores. Esta é a Função de Distribuição Preditiva Posterior, também conhecida como Função de Distribuição Cumulativa (CDF). |
| Exemplo | MODEL_PERCENTILE( SUM([Sales]),COUNT([Orders])) |
MODEL_QUANTILE
| Sintaxe | MODEL_QUANTILE(
|
| Definição | Retorna um valor numérico de destino dentro do intervalo provável definido pela expressão de destino e outros preditores, em um quantil especificado. Este é o Quantil Preditivo Posterior. |
| Exemplo | MODEL_QUANTILE(0.5, SUM([Sales]), COUNT([Orders])) |
A eficiência das funções de modelagem preditiva
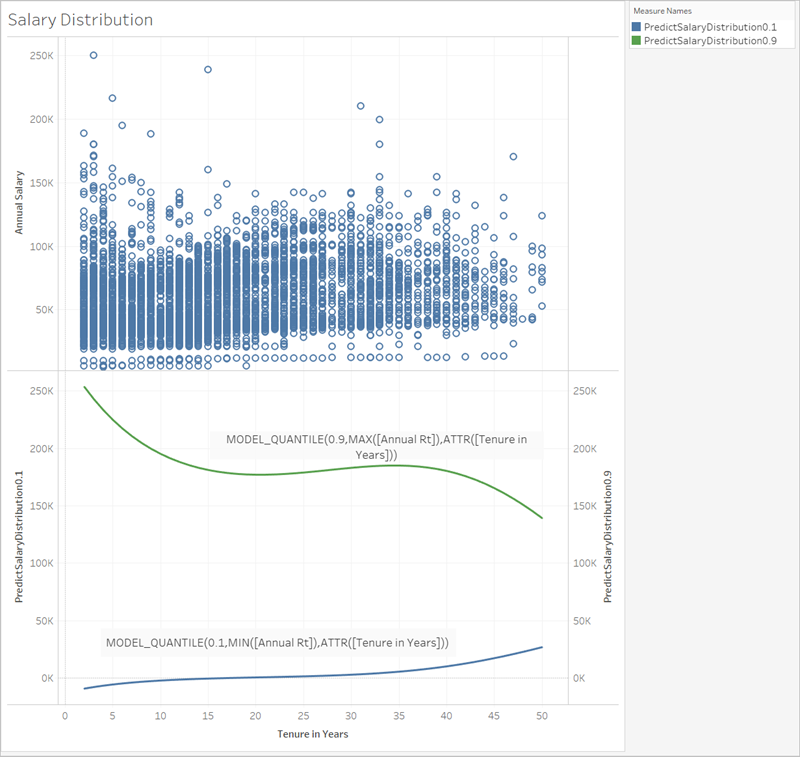
Vejamos um exemplo que usa dados salariais, começando com MODEL_QUANTILE.
No exemplo abaixo, a função MODEL_QUANTILE foi usada para exibir 10% e 90% da distribuição esperada para o mesmo conjunto de dados. Com base nos dados existentes e utilizando um modelo de regressão linear, o mecanismo estatístico determinou que há uma probabilidade de 90% de que o salário máximo para cada cargo esteja abaixo da linha verde e uma probabilidade de 10% de que o salário mínimo para cada cargo esteja abaixo da linha azul.
Em outras palavras, com o quantil definido em 0,9, o modelo prevê que todos os salários estarão na linha verde de 90% ou abaixo dela. A linha azul foi definida como 0,1 ou 10%, de modo que apenas 10% dos salários estarão na linha azul ou abaixo dela, e o contrário disso (90%) ficará acima da linha azul.
Efetivamente, isso fornece uma faixa em que podemos prever que estarão 80% dos pontos futuros possivelmente gerados ou dados não observados.
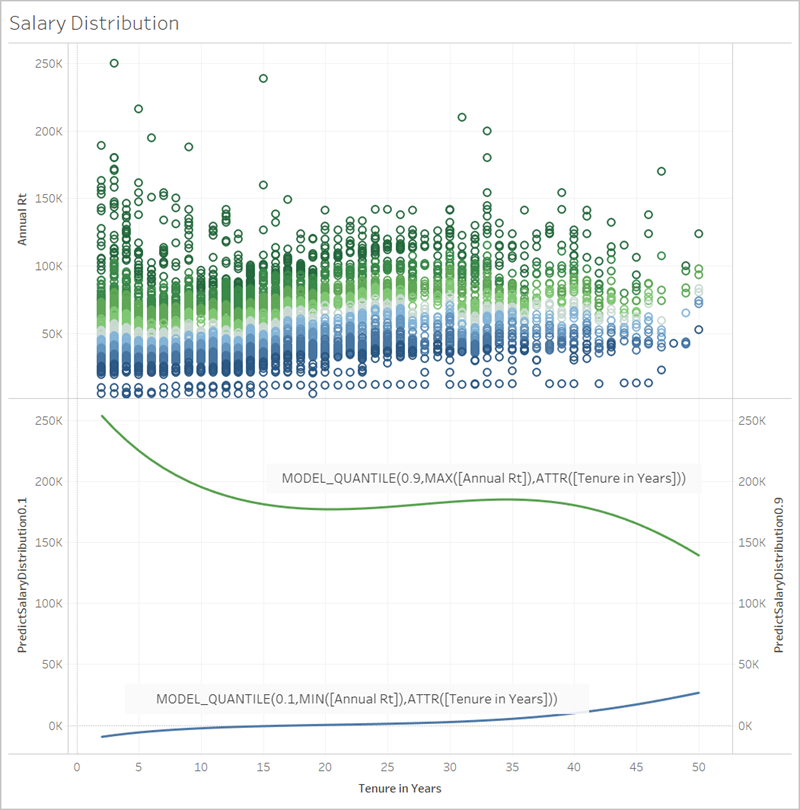
Em seguida, vamos ver como MODEL_PERCENTILE, o inverso de MODEL_QUANTILE, pode ajudar a entender melhor os dados.
Você pode identificar as exceções do conjunto de dados usando a função MODEL_PERCENTILE. A função MODEL_PERCENTILE informa, como percentil, onde está a marca observada em uma faixa de valores prováveis para cada marca. Se o percentil estiver muito próximo de 0,5, o valor observado está muito próximo do valor médio previsto. Se o percentil estiver próximo de 0 ou 1, o valor observado está nos limites inferiores ou superiores do intervalo gama do modelo e é relativamente inesperado.
Abaixo, aplicamos a função MODEL_PERCENTILE como cor à visualização salarial na metade superior da imagem, para ajudar a entender quais valores são mais esperados.
Sintaxe detalhada das funções de modelagem preditiva
O que é MODEL_QUANTILE?
A função MODEL_QUANTILE calcula o quantil preditivo posterior ou o valor esperado em um quantil especificado.
- Quantil: o primeiro argumento é um número entre 0 e 1, que indica que o quantil deve ser previsto. Por exemplo, 0,5 especifica que a mediana será prevista.
- Expressão de destino: o segundo argumento é a medida para a previsão ou "destino".
- Expressões de preditor: o terceiro argumento é o preditor usado para fazer a previsão. Os preditores podem ser dimensões, medidas ou ambos.
O resultado é um número dentro do intervalo provável.
Você pode usar a função MODEL_QUANTILE para gerar um intervalo de confiança, valores ausentes (como datas futuras) ou categorias que não existem no conjunto de dados subjacente.
O que é MODEL_PERCENTILE?
MODEL_PERCENTILE calcula a função de distribuição preditiva posterior, também conhecida como Função de Distribuição Cumulativa (CDF). Essa função calcula o quantil de determinado valor entre 0 e 1, o contrário de MODEL_QUANTILE.
- Expressão de destino: o primeiro argumento é a medida a ser direcionada, que identifica quais valores a serem avaliados.
- Expressões de preditor: o segundo argumento é o preditor usado para fazer a previsão.
- Argumentos adicionais são opcionais e são incluídos para controlar a previsão.
Observe que a sintaxe de cálculo é semelhante, mas MODEL_QUANTILE tem o argumento extra de um quantil definido.
O resultado é a probabilidade de o valor esperado ser menor ou igual ao valor observado expresso na marca.
Você pode usar a função MODEL_PERCENTILE para obter correlações e relações no banco de dados. Se MODEL_PERCENTILE retornar um valor próximo a 0,5, a marca observada está próxima da mediana do intervalo de valores previstos, considerando os outros preditores selecionados. Se MODEL_PERCENTILE retornar um valor próximo a 0 ou 1, a marca observada está próxima do intervalo inferior ou superior do que o modelo espera, considerando os outros preditores selecionados.
Para usuários avançados, existem dois outros argumentos opcionais que você pode incluir para controlar a previsão. Para obter mais informações, consulte Regularização e aumento na modelagem preditiva.
O que está sendo calculado?
A entrada usada para criar o modelo é uma matriz em que cada marca é uma linha e as colunas são a expressão de destino e as expressões de preditor avaliadas para cada marca. Qualquer linha especificada na visualização define a linha para o conjunto de dados calculado pelo mecanismo estatístico.
Vejamos o exemplo abaixo, onde as linhas (e, portanto, as marcas) são definidas por cargos e as colunas são a expressão de destino MEDIAN([Annual Rt]). Elas são seguidas pelos preditores adicionais opcionais MEDIAN([Tenure in Months (Measure)] e ATTR([Department Generic (group)].
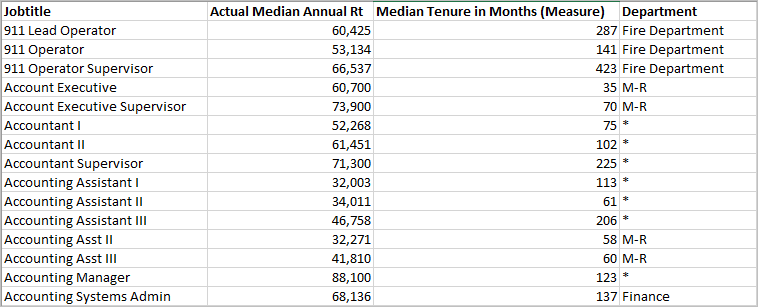
Para obter mais informações sobre os dados utilizados para criar um modelo e gerar previsões, consulte Uso de computação e particionamento de dados na modelagem preditiva.
Quais modelos são aceitos?
Funções de modelagem preditiva aceitam regressão linear, regressão linear regularizada e regressão do processo gaussiano. Esses modelos aceitam diferentes casos de uso e tipos de previsão, além de terem diferentes limitações. Para obter mais informações, consulte Escolha de um modelo preditivo.
Escolha dos preditores
Um preditor pode ser qualquer campo na fonte de dados – medida ou dimensão – incluindo campos calculados.
Por exemplo, suponha que você tenha um conjunto de dados que inclua os campos [Cidade], [Estado] e [Região], onde existem vários registros de [Cidade] e vários registros de [Estado] em uma [Região].
Em uma visualização que usa [Estado] como marca, os preditores ATTR([State]) e ATTR([Region]) funcionarão como preditores. No entanto, o preditor ATTR([City]) será revertido para *, uma vez que existem várias cidades em um estado visualizado e, portanto, não podem ser usadas como preditores. Em outras palavras, incluir um preditor que está em um nível de detalhe menor do que a visualização não agrega valor às previsões. Na maioria dos casos, um preditor com um nível de detalhe menor do que a visualização será avaliado como * e, portanto, todos serão tratados de forma idêntica.
No entanto, se o mesmo conjunto de dados for usado para gerar uma visualização que usa [Cidade] como marca, ATTR([City]), ATTR([State]) e ATTR([Region]) podem ser usados com sucesso como preditores. Para obter mais informações sobre o uso das funções ATTR, consulte Quando usar a função Atributo (ATTR).
As dimensões e medidas não precisam ser visualizadas (na exibição ou visualização) para serem incluídas como preditores. Para obter orientações mais detalhadas, consulte Escolha de preditores.
Recomendações
Os cálculos de previsão são melhor utilizados da seguinte forma:
Para prever os valores dos registros individuais, onde cada marca na visualização representa uma entidade separada, como produto, venda, pessoa, etc., em vez de dados agregados. Isso ocorre porque o Tableau considera cada marca igualmente provável, mesmo que uma marca seja composta por 100 registros e as outras marcas sejam compostas por um registro cada. O mecanismo estatístico não pondera as marcas com base no número de registros que as compõe.
- Para prever os valores das expressões de destino agregadas que usam SUM e COUNT.
Limitações
Você deve usar um campo calculado para estender uma série temporal para o futuro. Para obter mais informações, consulte Previsão do futuro.
Os preditores devem estar no mesmo nível de detalhe que a exibição ou acima. Ou seja, se sua a exibição é agregada por estado, você deve usar estado ou região como preditor, mas não cidade. Para obter mais informações, consulte Escolha de preditores.
Quando os cálculos de previsão serão interrompidos?
Independentemente do modelo que você está usando, deve ter pelo menos três pontos de dados dentro de cada partição para que o modelo retorne uma resposta.
Se você especificou a regressão do processo gaussiano como seu modelo, ele pode ser usado em cálculos preditivos com um preditor dimensional ordenado e qualquer número de preditores não ordenados dimensionais. As medidas não são aceitas como preditores nos cálculos de regressão do processo gaussiano, mas podem ser usadas em cálculos lineares e regularizados de regressão linear. Para obter mais informações sobre a seleção deste modelo, consulte Escolha de um modelo preditivo.
Se o cálculo usasse ATTR[State] como preditor e a visualização também incluísse Estado como marca, mas nenhum outro campo em um nível de detalhe menor, como Cidade, então você retornaria um erro. Para evitar isso, basta verificar se existe uma relação de um para um entre marcas e categorias de preditor.
Para obter mais informações sobre esses e outros problemas de previsão, consulte Resolver erros nas funções de modelagem preditiva.
Perguntas frequentes
E as marcas em vários grupos de preditor?
Se uma linha for agregada a partir de dados que existem em vários grupos de preditor, o valor da função ATTR é um valor especial de vários valores. Por exemplo, todas as cidades que existem em vários estados terão o mesmo valor previsto (a menos que haja outros preditores distintos). Ao selecionar os preditores, é melhor usar preditores que estejam no mesmo nível de detalhe que a visualização ou acima. Novamente, para obter mais informações sobre as funções ATTR, consulte Quando usar a função Atributo (ATTR).
E se a agregação ATTR retornar um valor *?
* é tratado como um valor separado. Se ATTR retornar * para todas as marcas, então você basicamente tem um preditor com um valor constante, que será ignorado. É o mesmo que não incluir esse preditor.
Se ATTR retornar * para algumas marcas, mas não todas, então será tratada como uma categoria em que todos os valores * são considerados iguais. Esse cenário é idêntico ao cenário acima, em que existem marcas em vários grupos de preditor.
E as opções do menu de cálculo de tabela "Uso de computação"?
Funciona de forma idêntica ao Uso de computação em outros cálculos de tabela. Para obter mais informações, consulte Uso de computação e particionamento de dados na modelagem preditiva.
Por que estou recebendo um erro?
Existem várias razões pelas quais você pode estar encontrando um erro ao usar as funções de modelagem preditiva. Para obter as etapas detalhadas de solução de problemas, consulte Resolver erros nas funções de modelagem preditiva.