Tableau Prep vous aide à nettoyer et à organiser vos données pour l’analyse. La première étape de ce processus consiste à identifier les données avec lesquelles vous allez travailler.
Remarque : depuis la version 2020.4.1, vous pouvez également créer et modifier des flux dans Tableau Server et Tableau Cloud. Les informations de cette rubrique s’appliquent à toutes les plates-formes, sauf mention spécifique. Pour plus d’informations sur la création de flux sur le Web, consultez Tableau Prep sur le Web(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Server.
Vous pouvez vous connecter à vos données en utilisant l’un des éléments suivants :
Se connecter via des connecteurs intégrés pour les types de données courants
La manière la plus courante de se connecter aux données est d’utiliser les connecteurs intégrés dans Tableau Prep Builder. Ceux-ci sont disponibles pour les types de données les plus courants, et de nouveaux connecteurs sont ajoutés fréquemment avec les nouvelles versions de Tableau Prep Builder. Pour voir la liste des connecteurs disponibles, ouvrez Tableau Prep Builder ou démarrez un flux sur le Web, puis cliquez sur le bouton Ajouter une connexion  pour voir si le volet gauche contient les connecteurs disponibles sous Connexion.
pour voir si le volet gauche contient les connecteurs disponibles sous Connexion.
La plupart des connecteurs intégrés fonctionnent de la même manière sur toutes nos plates-formes et sont décrits dans la rubrique Connecteurs pris en charge(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Desktop.
Remarque : lors de la connexion à une source de données, n’utilisez pas le nom réservé « Nombre d’enregistrements » pour un nom de champ ou un champ calculé. L’utilisation de ce nom réservé entraînera une erreur liée aux autorisations.
Considérations sur l’utilisation de connecteurs intégrés
Si vous ouvrez un flux dans une version où le connecteur n’est pas pris en charge, le flux peut s’ouvrir mais risque de présenter des erreurs ou de ne pas s’exécuter, à moins que les connexions de données ne soient supprimées.
- Lors de l’utilisation d’un connecteur basé sur MySQL, par défaut, la connexion est sécurisée lorsque SSL est activé. Par contre, Tableau Prep Builder ne prend pas en charge les connexions SSL personnalisées basées sur des certificats pour les connecteurs basés sur MySQL.
À compter de la version 2025.1, vous pouvez vous connecter à des sources de données sur site, publier votre flux sur Tableau Cloud et l’exécuter de manière programmée. Vous aurez besoin d’un client Tableau Bridge configuré dans un pool de clients Bridge, en ajoutant le domaine à la Liste d’autorisations de réseau privé. Dans Tableau Prep Builder et sur le Web, lorsque vous vous connectez à votre source de données, assurez-vous que l’URL du serveur correspond au domaine du pool Bridge. Pour plus d’informations, consultez Bases de données dans la rubrique « Publier un flux sur Tableau Server ou Tableau Cloud ».
Certains connecteurs, présentés dans les sections ci-dessous, ont des exigences différentes lorsqu’ils sont utilisés avec Tableau Prep Builder.
Se connecter aux sources de données cloud à l’aide de Tableau Server ou Tableau Cloud
Vous pouvez vous connecter à des sources de données cloud dans Tableau Prep comme vous le faites dans Tableau Desktop. Par contre, si vous prévoyez de publier des flux qui se connectent aux sources de données cloud et de les exécuter de manière programmée sur votre serveur, vous devrez configurer vos identifiants dans Tableau Server ou Tableau Cloud.
Vous configurez vos informations d’identification dans l’onglet Paramètres de la page Paramètres de Mon compte et vous vous connectez à l’entrée de votre connecteur cloud en utilisant ces mêmes informations d’identification.
Tableau Prep Builder
Lors de la publication du flux, dans la boîte de dialogue Publier, cliquez sur Modifier pour modifier la connexion, puis dans le menu déroulant Authentification, sélectionnez Intégrer <vos identifiants>.
Vous pouvez également ajouter des informations d’identification directement à partir de la boîte de dialogue Publier (Tableau Prep Builder version 2020.1.1 et versions ultérieures) lors de la publication de votre flux, puis les intégrer automatiquement dans votre flux lors de la publication. Pour plus d’informations, consultez Publier un flux depuis Tableau Prep Builder.
Si vous n’avez pas configuré les informations d’identification enregistrées et que vous sélectionnez Inviter l’utilisateur dans le menu déroulant Authentification , après avoir publié le flux, vous devez modifier la connexion et saisir vos informations d’identification dans l’onglet Connexions dans Tableau Server ou Tableau Cloud, sinon le flux échouera lors de l’exécution.
Tableau Prep sur le Web
Dans la création Web, vous pouvez intégrer des informations d’identification à partir du menu supérieur sous Fichier > Identifiants de connexion. Pour plus d’informations, consultez Publier des flux(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Server.
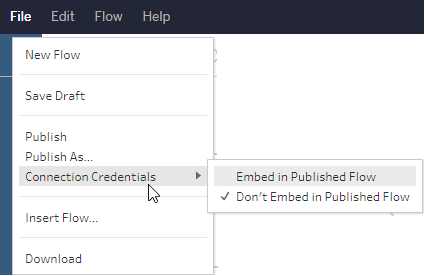
Dans Tableau Prep Builder version 2019.4.1, les connecteurs cloud suivants ont été ajoutés et sont également disponibles lors de la création ou de la modification de flux sur le Web :
- Box
- DropBox
- Google Drive
- OneDrive
Pour plus d’informations sur la connexion à vos données à l’aide de ces connecteurs, consultez la rubrique d’aide consacrée aux connecteurs(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Desktop.
Se connecter à des données Salesforce
Pris en charge dans Tableau Prep Builder à partir de la version 2020.2.1 et lors de la création de flux sur le Web dans Tableau Server et Tableau Cloud à partir de la version 2020.4.
Tableau Prep Builder prend en charge la connexion aux données à l’aide du connecteur Salesforce, tout comme Tableau Desktop, mais avec quelques différences.
- Tableau Prep Builder prend en charge tout type de jointure de votre choix.
- SQL personnalisé peut être créé dans Tableau Prep Builder 2022.1.1 ou version ultérieure. Les flux qui utilisent SQL personnalisé peuvent être exécutés et les étapes existantes peuvent être modifiées dans la version 2020.2.1 ou ultérieure.
- L’utilisation d’une connexion standard pour créer votre propre connexion personnalisée n’est pas prise en charge actuellement.
- Vous ne pouvez pas modifier le nom de la source de données par défaut pour choisir un nom unique ou personnalisé.
- Si vous prévoyez de publier des flux sur Tableau Server et que vous souhaitez utiliser les informations d’identification enregistrées, l’administrateur du serveur devra configurer Tableau Server avec un ID de client OAuth et un secret sur le connecteur. Pour plus d’informations, voir Modifier Salesforce.com OAuth sur des informations d’identification enregistrées(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Server.
- Pour exécuter une actualisation incrémentielle sur les entrées de flux qui utilisent le connecteur Salesforce, vous devez utiliser Tableau Prep Builder version 2021.1.2 ou ultérieure. Pour plus d’informations sur l’utilisation de l’actualisation incrémentielle, consultez Actualiser les données de flux à l’aide d’une actualisation incrémentielle.
Tableau Prep importe les données en créant un extrait. Seuls les extraits sont actuellement pris en charge pour Salesforce. Le chargement de l’extrait initial peut prendre un certain temps en fonction de la quantité de données incluse. Vous verrez une minuterie dans l’étape des données entrantes pendant le chargement des données.
Pour plus d’informations sur l’utilisation du connecteur Salesforce, consultez Salesforce(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Desktop et la création Web.
Connexion à Salesforce Data Cloud
Vous pouvez vous connecter aux données qui utilisent Salesforce Data Cloud à l’aide du connecteur Salesforce Data Cloud (publié dans Tableau Cloud en octobre 2023). Pour plus d’informations, consultez Connecter la création Web Tableau Cloud à Salesforce Data Cloud(Le lien s’ouvre dans une nouvelle fenêtre).
Pour vous connecter aux données Salesforce Data Cloud, utilisez le connecteur Salesforce Data Cloud. Le connecteur Salesforce Data Cloud reconnaît les espaces de données, présente des étiquettes d’objet plus claires et est optimisé par des requêtes accélérées.
- Dans le volet Connexions, sélectionnez Salesforce Data Cloud dans la liste des connecteurs Tableau Server.
- Dans la boîte de dialogue Salesforce Data Cloud, cliquez sur Connexion.
- Connectez-vous à Salesforce avec votre nom d’utilisateur et votre mot de passe.
- Sélectionnez Autoriser.
- Fermez le volet du navigateur.
- Dans Tableau Prep, sélectionnez un espace de données pour afficher les tables.
- Sélectionnez une table.
Se connecter aux données Google BigQuery
Tableau Prep Builder prend en charge la connexion aux données à l’aide de Google BigQuery, tout comme Tableau Desktop.
Vous devez configurer les informations d’identification pour que Tableau Prep communique avec Google BigQuery. Si vous prévoyez de publier des flux sur Tableau Server ou Tableau Cloud, les connexions OAuth doivent également être configurées pour ces applications.
Remarque : Tableau Prep ne prend actuellement pas en charge l’utilisation des attributs de personnalisation de Google BigQuery.
Configurer SSL pour se connecter à Google BigQuery (MacOS uniquement)
Si vous utilisez Tableau Prep Builder sur Mac et que vous utilisez un proxy pour vous connecter à BigQuery, vous devez modifier la configuration SSL pour vous connecter à Google BigQuery
Remarque : aucune étape supplémentaire n’est requise pour les utilisateurs de Windows.
Pour configurer SSL pour les connexions OAuth à Google BigQuery, suivez les étapes suivantes :
- Exportez le certificat SSL de votre proxy vers un fichier, par exemple proxy.cer. Vous pouvez trouver votre certificat dans
Applications > Utilities > Keychain Access >System > Certificates (under Category). Localisez la version de java que vous utilisez pour exécuter Tableau Prep Builder. Par exemple : /Applications/Tableau Prep Builder 2020.4.app/Plugins/jre/lib/security/cacerts
Ouvrez l’invite de commande Terminal et exécutez la commande suivante pour votre version de Tableau Prep Builder :
Remarque : la commande keytool doit être exécutée à partir du répertoire qui contient la version de java que vous utilisez pour exécuter Tableau Prep Builder. Vous devrez peut-être modifier les répertoires avant d’exécuter cette commande. Par exemple : cd /Users/tableau_user/Desktop/SSL.cer -keystore Tableau Prep Builder 2020.1.1/Plugins/jre/bin. Ensuite, lancez la commande keytool.
keytool –import –trustcacerts –file /Users/tableau_user/Desktop/SSL.cer -keystore Tableau Prep Builder <version>/Plugins/jre/lib/security/cacerts -storepass changeit
Exemple : keytool –import –trustcacerts –file /Users/tableau_user/Desktop/SSL.cer -keystore Tableau Prep Builder 2020.4.1/Plugins/jre/lib/security/cacerts -storepass changeit
Si un message FileNotFoundException (accès refusé) s’affiche lors de l’exécution de la commande keytool, essayez d’exécuter la commande avec des autorisations élevées. Par exemple : sudo keytool –import –trustcacerts –file /Users/tableau_user/Desktop/SSL.cer -keystore Tableau Prep Builder 2020.4.1/Plugins/jre/lib/security/cacerts -storepass changeit.
Configurer et gérer vos informations d’identification Google BigQuery
Les informations d’identification que vous utilisez pour vous connecter à Google BigQuery à l’étape des données entrantes doivent correspondre aux informations d’identification définies dans l’onglet Paramètres de la page Mes paramètres de compte pour Google BigQuery dans Tableau Server ou Tableau Cloud.
Si vous sélectionnez des informations d’identification différentes ou aucune information d’identification dans votre paramètre d’authentification lors de la publication de votre flux, le flux échouera avec une erreur d’authentification jusqu’à ce que vous modifiiez la connexion pour le flux dans Tableau Server ou Tableau Cloud.
Pour modifier les informations d’identification, procédez comme suit :
- Dans Tableau Server ou Tableau Cloud, dans l’onglet Connexions, sur la connexion Google BigQuery, cliquez sur Plus d’actions
 .
. - Sélectionnez Modifier la connexion.
- Sélectionnez les informations d’identification enregistrées qui sont configurées dans l’onglet Paramètres de la page Paramètres de Mon compte.
Se connecter avec un fichier de Compte de service (JSON)
Pris en charge dans Tableau Prep Builder à partir de la version 2021.3.1. L’accès au Compte de service n’est pas disponible lors de la création de flux sur le Web.
- Ajoutez un Compte de service en tant qu’informations d’identification enregistrées. Pour plus d’informations, consultez Modifier Google OAuth pour utiliser les informations d’identification enregistrées(Le lien s’ouvre dans une nouvelle fenêtre).
- Connectez-vous à Google BigQuery en utilisant votre e-mail ou votre numéro de téléphone, puis sélectionnez Suivant.
- Dans Authentification, sélectionnez Se connecter avec un fichier de Compte de service (JSON).
- Entrez le chemin d’accès du fichier ou utilisez le bouton Parcourir pour le rechercher.
- Cliquez sur Connexion.
- Entrez votre mot de passe pour continuer.
- Sélectionnez Accepter pour autoriser Tableau à accéder à vos données Google BigQuery. Vous serez invité à fermer le navigateur.
Se connecter avec OAuth
Pris en charge dans Tableau Prep Builder à partir de la version 2020.2.1 et lors de la création de flux sur le Web dans Tableau Server et Tableau Cloud à partir de la version 2020.4.
- Connectez-vous à Google BigQuery en utilisant votre e-mail ou votre numéro de téléphone, puis sélectionnez Suivant.
- Dans Authentification, sélectionnez Se connecter avec OAuth.
- Cliquez sur Connexion.
- Entrez votre mot de passe pour continuer.
- Sélectionnez Accepter pour autoriser Tableau à accéder à vos données Google BigQuery. Vous serez invité à fermer le navigateur.
Pour plus d’informations sur la configuration et la gestion de vos informations d’identification, consultez les rubriques suivantes :
Gérer vos paramètres de compte(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Desktop et l’aide de la création Web.
Publier un flux depuis Tableau Prep Builder(Le lien s’ouvre dans une nouvelle fenêtre) pour obtenir des informations sur le paramétrage des options d’authentification lors de la publication d’un flux.
Afficher et résoudre les erreurs(Le lien s’ouvre dans une nouvelle fenêtre) pour obtenir des informations sur la résolution des erreurs de connexion dans Tableau Server ou Tableau Cloud.
Se connecter aux données SAP HANA
Pris en charge dans Tableau Prep Builder à partir de la version 2019.2.1 et lors de la création de flux sur le Web dans Tableau Server et Tableau Cloud à partir de la version 2020.4.
Tableau Prep Builder prend en charge la connexion aux données à l’aide de SAP HANA, tout comme Tableau Desktop, mais avec quelques différences.
Connectez-vous à la base de données à l’aide de la même procédure que celle utilisée dans Tableau Desktop. Pour plus d’informations, consultez SAP HANA(Le lien s’ouvre dans une nouvelle fenêtre). Après vous être connecté et avoir recherché votre table, faites glisser la table vers l’espace de travail pour commencer à créer votre flux.
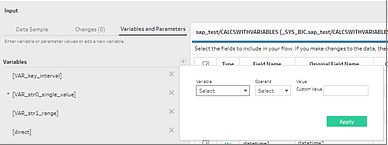
Les invites liées aux variables et aux paramètres lors de l’ouverture d’un flux ne sont pas prises en charge dans Tableau Prep. Au lieu de cela, dans le volet Entrée, cliquez sur l’onglet Variables et paramètres et sélectionnez les variables et les opérandes que vous souhaitez utiliser, puis faites votre choix dans une liste de valeurs prédéfinies ou entrez des valeurs personnalisées pour interroger votre base de données et renvoyer les valeurs dont vous avez besoin.
Tableau Prep Builder et Tableau Prep Conductor ne prennent pas en charge les variables et les paramètres lors de la connexion à une source de données publiée SAP HANA.
Remarque : depuis Tableau Prep Builder version 2019.2.2 et sur le Web à partir de la version 2020.4.1, vous pouvez utiliser SQL initial pour interroger votre connexion. Si vous avez plusieurs valeurs pour une variable, vous pouvez sélectionner la valeur dont vous avez besoin dans une liste déroulante.
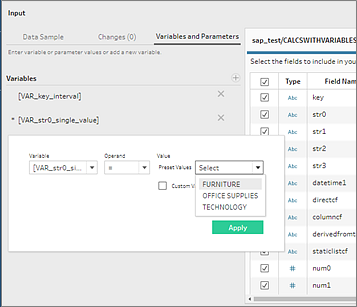
Vous pouvez également ajouter des variables supplémentaires. Cliquez sur le bouton  plus dans la section Variables et sélectionnez une variable et un opérande, puis entrez une valeur personnalisée.
plus dans la section Variables et sélectionnez une variable et un opérande, puis entrez une valeur personnalisée.
Remarque : ce connecteur requiert Tableau Server version 2019.2 et versions ultérieures pour exécuter le flux de manière programmée. Si vous utilisez une version de serveur antérieure, vous pouvez actualiser les données de flux à l’aide de l’interface de ligne de commande. Pour plus d’informations sur l’exécution de flux depuis la ligne de commande, consultez Actualiser les fichiers de sortie du flux depuis la ligne de commande(Le lien s’ouvre dans une nouvelle fenêtre). Pour plus d’informations sur la compatibilité des versions, consultez Compatibilité de version avec Tableau Prep(Le lien s’ouvre dans une nouvelle fenêtre).
Se connecter à des fichiers et des bases de données spatiales
Pris en charge dans Tableau Prep Builder à partir de la version 2020.2.1 et lors de la création de flux sur le Web dans Tableau Server et Tableau Cloud à partir de la version 2020.4.
Vous pouvez vous connecter à des fichiers de données spatiales et à des sources de données spatiales dans Tableau Prep Builder ou lors de la création ou de la modification de flux sur le Web.
Tableau Prep prend en charge les types de connexion suivants :
- Formats de fichier de données spatiales
- Tableau Prep Builder : fichiers de formes Esri, bases de données géographiques de fichiers Esri, KML, TopoJSON, GeoJSON, extraits, MapInfo MID/MIF, fichiers TAB et fichiers de formes compressés.
- Tableau Server et Tableau Cloud : fichiers de formes compressés, KML, TopoJSON, GeoJSON, bases de données géographiques de fichiers Esri et extraits.
- Bases de données spatiales (Amazon Redshift, Microsoft SQL Server, Oracle et PostgreSQL).
Vous pouvez également combiner des tables spatiales avec des tables non spatiales à l’aide d’une jointure standard et envoyer des données spatiales à un fichier d’extrait (.hyper). Les fonctions spatiales, les jointures spatiales via des intersections et la visualisation de données spatiales sur une carte Tableau Prep ne sont pas prises en charge actuellement.
Opérations de nettoyage prises en charge
Lorsque vous travaillez avec des données de fichiers de formes, certaines opérations de nettoyage ne sont pas prises en charge. Seules les opérations de nettoyage suivantes sont disponibles dans Tableau Prep lorsque vous utilisez des données de fichier de formes.
- Filtres : uniquement pour supprimer les valeurs null ou inconnues
- Renommer le champ
- Dupliquer le champ
- Conserver uniquement le champ
- Supprimer le champ
- Créer un champ calculé
Avant de vous connecter
Avant de vous connecter à des fichiers de données spatiales, assurez-vous que les fichiers suivants sont dans le même répertoire :
- Fichiers de formes Esri : Le dossier doit contenir des fichiers .shp, .shx, .dbf et .prj, ainsi que les fichiers .zip du fichier de formes Esri.
- Bases de données géographiques de fichiers Esri : le dossier doit contenir le fichier .gdb ou .zip de la base de données géographiques du fichier.
- Fichiers KML : le dossier doit contenir le fichier .kml. (Aucun autre fichier n’est requis.)
- Fichiers GeoJSON : le dossier doit contenir le fichier .geojson (aucun autre fichier n’est requis.)
- Fichiers TopoJSON : le dossier doit contenir le fichier .json ou .topojson. (Aucun autre fichier n’est requis.)
Se connecter à des fichiers de données spatiales
Effectuez l’une des actions suivantes :
- Ouvrez Tableau Prep Builder et cliquez sur le bouton Ajouter une connexion .
- Ouvrez Tableau Server ou Tableau Cloud. À partir du menu Explorer, cliquez sur Nouveau > Flux.
Dans la liste des connecteurs, sélectionnez Fichier de données spatiales.
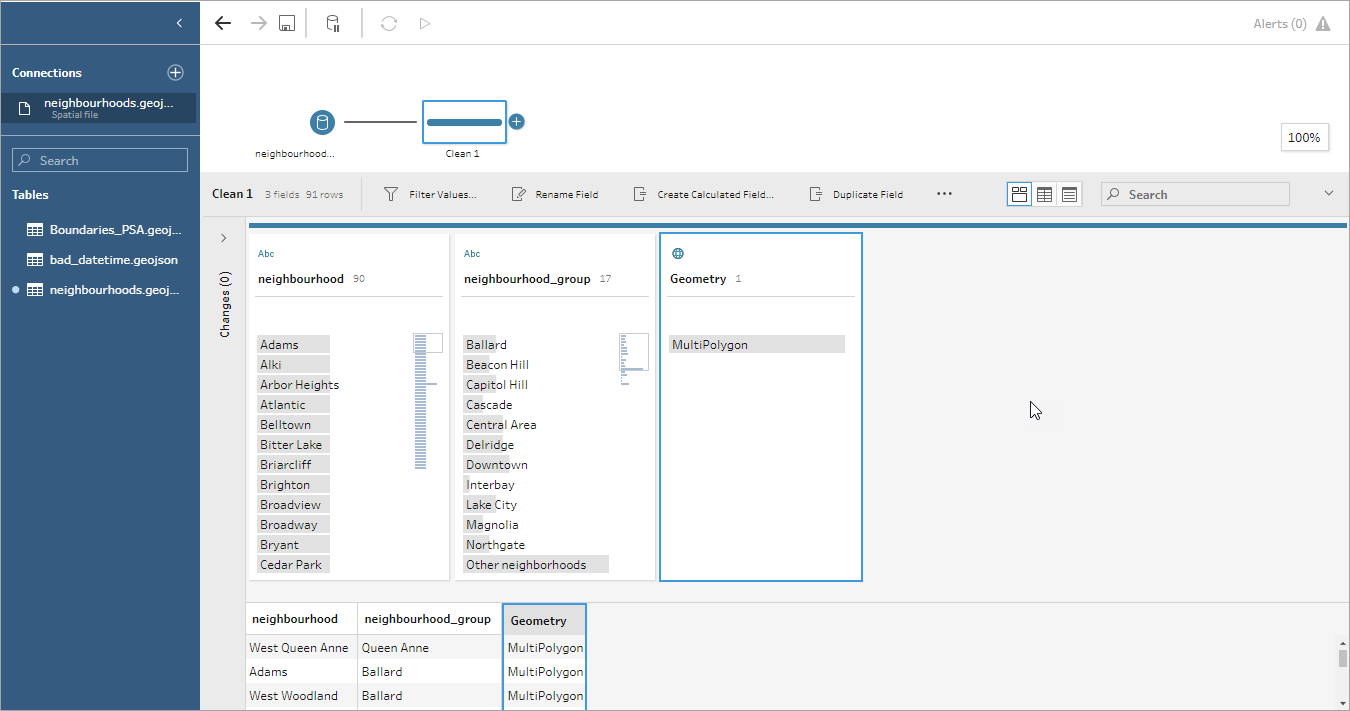
Les champs de données spatiales sont affectés au type de données spatiales et ne peuvent pas être modifiés. Si les champs proviennent d’un fichier de données spatiales, le champ se voit attribuer un nom de champ par défaut, « Geometry ». Si les champs proviennent d’une base de données spatiales, les noms de champ de base de données sont affichés. Si Tableau ne peut pas déterminer le type de données, le champ s’affiche sous le nom « Null ».
Se connecter à l’aide d’ODBC
Pris en charge dans Tableau Prep Builder à partir de la version 2019.2.2. Ce type de connecteur n’est pas encore pris en charge pour la création de flux sur le Web.
Si vous avez besoin de vous connecter à des sources de données ne figurant pas dans le volet Connexions, vous pouvez vous connecter à n’importe quelle source de données avec le connecteur Autres bases de données (ODBC) qui prend en charge la norme SQL et implémente l’API ODBC. La connexion aux données à l’aide du connecteur Autres bases de données (ODBC) fonctionne comme dans Tableau Desktop, à quelques différences près :
Vous ne pouvez vous connecter qu’avec l’option DSN (nom de la source de données).
Pour publier et exécuter votre flux dans Tableau Server, le serveur doit être configuré avec un DSN correspondant.
Remarque : l’exécution, depuis la ligne de commande, de flux qui incluent le connecteur Autres bases de données (ODBC) n’est pas prise en charge actuellement.
Il existe une expérience de connexion unique à la fois pour Windows et MacOS. Les invites liées aux attributs de connexion pour les pilotes ODBC (Windows) ne sont pas prises en charge.
Seuls les pilotes 64 bits sont pris en charge par Tableau Prep Builder.
Avant de vous connecter
Pour vous connecter à vos données à l’aide du connecteur Autres bases de données (ODBC), vous devez installer le pilote de base de données et configurer votre DSN (nom de la source de données). Pour publier et exécuter des flux vers Tableau Server, le serveur doit également être configuré avec un DSN correspondant.
Important : Tableau Prep Builder ne prend en charge que les pilotes 64 bits. Si vous avez déjà installé et configuré un pilote 32 bits, vous devrez peut-être le désinstaller, puis installer la version 64 bits si le pilote n’autorise pas l’installation simultanée des deux versions.
Créez un DSN à l’aide de l’Administrateur de source de données ODBC (64 bits) (Windows) ou de l’utilitaire ODBC Manager (MacOS).
Si l’utilitaire n’est pas installé sur votre Mac, vous pouvez en télécharger un depuis (www.odbcmanager.net(Le lien s’ouvre dans une nouvelle fenêtre) par exemple) ou vous pouvez modifier manuellement le fichier odbc.ini.
Dans l’Administrateur de sources de données ODBC (64 bits) (Windows) ou dans l’utilitaire ODBC Manager (MacOS), ajoutez une nouvelle source de données, sélectionnez le pilote de la source de données et cliquez sur Terminer.
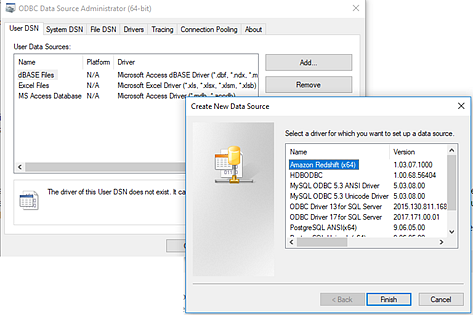
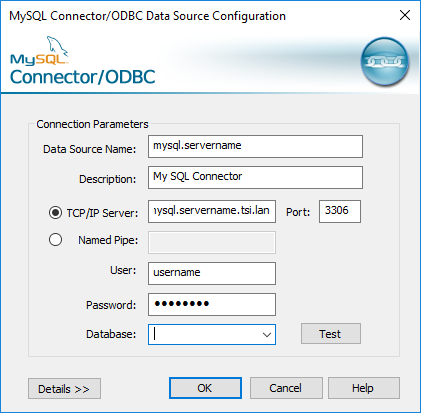
Dans la boîte de dialogue Configuration du pilote ODBC, saisissez les informations de configuration telles que le nom du serveur, le port, le nom d’utilisateur et le mot de passe. Cliquez sur Tester (si votre boîte de dialogue comporte cette option) pour vérifier que votre connexion est correctement établie, puis enregistrez votre configuration.
Remarque : Tableau Prep Builder ne prenant pas en charge les invites liées aux attributs de connexion, vous devez donc définir ces informations lors de la configuration du DNS.
Cet exemple montre la boîte de dialogue de configuration d’un connecteur MySQL.
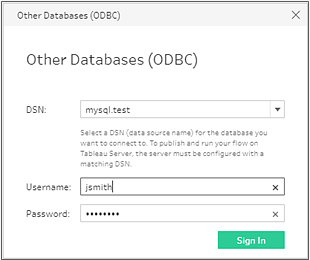
Connexion à l’aide d’autres bases de données (ODBC)
Ouvrez Tableau Prep Builder et cliquez sur le bouton Ajouter une connexion .
Dans la liste des connecteurs, sélectionnez Autres bases de données (ODBC).
Dans la boîte de dialogue Autres bases de données (ODBC), sélectionnez un DSN dans la liste déroulante et entrez le nom d’utilisateur et le mot de passe. Cliquez ensuite sur Connexion.
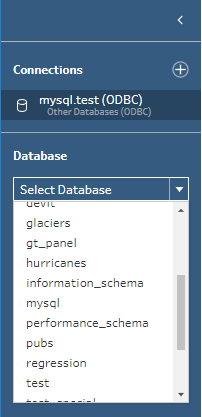
Dans le volet Connexions, sélectionnez votre base de données dans la liste déroulante.
Connexion aux données Microsoft Excel et nettoyage à l’aide de l’Interpréteur de données
Pris en charge pour les connexions directes à Microsoft Excel uniquement. L’interpréteur de données n’est actuellement pas disponible pour les fichiers Excel stockés dans des lecteurs cloud.
Lorsque vous travaillez avec des fichiers Microsoft Excel, vous pouvez utiliser l’Interpréteur de données pour détecter les sous-tables dans vos données et supprimer les informations superflues afin de préparer vos données pour l’analyse. Lorsque vous activez l’Interpréteur de données, il détecte ces sous-tables et les répertorie en tant que nouvelles tables dans la section Tables du volet Connexions. Vous pouvez aussi les déposer dans le volet Flux.
Si vous désactivez l’Interpréteur de données, ces tables sont supprimées du volet Connexions. Si ces tables sont déjà utilisées dans le flux, il en résulte des erreurs de flux provenant des données manquantes.
Remarque : actuellement, l’interpréteur de données détecte uniquement les sous-tables dans vos feuilles de calcul Excel et ne prend pas en charge la spécification de la ligne de départ pour les fichiers texte et les feuilles de calcul. De plus, les tables détectées par l’interpréteur de données ne sont pas incluses dans les résultats de recherche de l’union avec caractère générique.
L’exemple ci-dessous montre les résultats de l’utilisation de l’Interpréteur de données pour une feuille de calcul Excel dans le volet Connexions. L’Interpréteur de données a détecté deux sous-tables supplémentaires.
| Avant l’Interpréteur de données | Après l’Interpréteur de données |
|---|
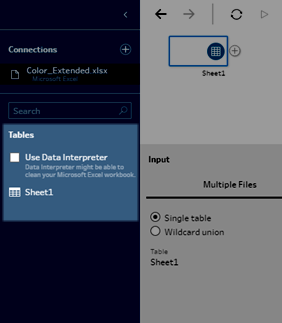 | 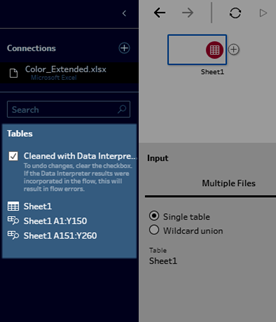 |
Pour utiliser l’Interpréteur de données, complétez les étapes suivantes :
Sélectionnez Se connecter aux données puis sélectionnez Microsoft Excel.
Sélectionnez votre fichier et cliquez sur Ouvrir.
Activez la case à cocher Utiliser l’interpréteur de données.
Faites glisser la nouvelle table vers le volet Flux pour l’inclure dans votre flux. Pour supprimer l’ancienne table, faites un clic droit sur l’étape des données entrantes pour l’ancienne table, et sélectionnez Supprimer.
Se connecter à l’aide de connecteurs personnalisés
Lorsque Tableau Prep ne fournit pas de connecteur intégré pour vos données basées sur ODBC et JDBC, vous pouvez utiliser un connecteur personnalisé. Vous pouvez :
Les connecteurs personnalisés pour les données basées sur ODBC et JDBC sont pris en charge dans Tableau Prep Builder version 2020.4.1 et versions ultérieures.
Pour les développeurs de connecteurs, voir Exécuter votre connecteur pour plus d’informations.
Certains connecteurs personnalisés nécessitent l’installation d’un pilote supplémentaire. Si une invite s’affiche pendant le processus de connexion, suivez les invites pour télécharger et installer le pilote requis. Les connecteurs personnalisés ne peuvent pas être utilisés avec Tableau Cloud à ce stade.
Utiliser des connecteurs créés par des partenaires
Des connecteurs créés par des partenaires ou d’autres connecteurs personnalisés sont disponibles dans le volet Connexion. Ces connecteurs sont répertoriés sous Connexions supplémentaires et sont également disponibles dans la page Connecteurs Tableau Exchange.
- Cliquez sur Connexions dans le volet de gauche.
- Dans la section Connecteurs supplémentaires du volet Connexion, cliquez sur le connecteur que vous souhaitez utiliser.
- Cliquez sur Installer et redémarrer Tableau.
Une fois le connecteur installé, il apparaît dans la section Vers un serveur du volet Connexion.
Remarque : si vous recevez un avertissement signalant un problème de chargement des connecteurs, installez le fichier .taco dont vous avez besoin depuis la page Connecteurs Tableau Exchange. Si vous êtes invité à installer les pilotes, accédez à Tableau Exchange pour obtenir des instructions et les emplacements de téléchargement du pilote.
Se connecter à des sources de données publiées
Les sources de données publiées sont celles que vous pouvez partager avec d’autres. Lorsque vous souhaitez mettre une source de données à la disposition d’autres utilisateurs, vous pouvez la publier depuis Tableau Prep Builder (version 2019.3.1 et supérieure) sur Tableau Server ou Tableau Cloud, ou en tant que sortie de votre flux.
Vous pouvez utiliser une source de données publiée comme source de données d’entrée pour votre flux, que vous travailliez dans Tableau Prep Builder ou sur le Web.
Remarque : lorsque vous publiez un flux qui inclut une source de données publiée en tant qu’entrée, le publicateur est désigné comme propriétaire par défaut du flux. Lors de son exécution, le flux utilise le propriétaire du flux pour le compte Exécuter en tant que. Pour plus d’informations sur le compte Exécuter en tant que, consultez Compte Exécuter en tant que service(Le lien s’ouvre dans une nouvelle fenêtre). Seul l’administrateur de site ou de serveur peut modifier le propriétaire du flux dans Tableau Server ou Tableau Cloud, et uniquement pour lui-même.
Tableau Prep Builder prend en charge :
Remarque : Tableau Prep Builder ne prend pas en charge les sources de données publiées qui incluent des données multidimensionnelles (cube), des connexions multi-serveurs ou des sources de données publiées avec des tables associées.
Tableau Server et Tableau Cloud prennent en charge :
À propos des informations d’identification et des autorisations :
- Vous devez posséder un rôle Explorer ou supérieur sur le site du serveur auquel vous êtes connecté pour vous connecter aux sources de données publiées. Seuls les utilisateurs dotés du rôle Creator peuvent créer ou modifier des flux sur le Web. Pour plus d’informations concernant les rôles sur le site, consultez Définir les rôles sur le site des utilisateurs(Le lien s’ouvre dans une nouvelle fenêtre) dans l’aide de Tableau Server.
- Dans Tableau Prep Builder, l’accès à la source de données est autorisé en fonction de l’identité de l’utilisateur connecté au serveur. Vous ne verrez que les données auxquelles vous avez accès.
Dans la création Web Prep (Tableau Server et Tableau Cloud), l’accès aux sources de données est également autorisé en fonction de l’identité de l’utilisateur connecté au serveur. Vous ne verrez que les données auxquelles vous avez accès.
Cependant, lorsque vous exécutez le flux manuellement ou de manière programmée, l’accès à la source de données est autorisé en fonction de l’identité du propriétaire du flux. Le dernier utilisateur à publier un flux devient le nouveau propriétaire du flux.
- Les administrateurs de site et de serveur peuvent modifier le propriétaire du flux, mais uniquement pour eux-mêmes.
- Les informations d’identification doivent être intégrées pour se connecter à la source de données publiée.
Conseil : si les informations d’identification ne sont pas intégrées pour la source de données, mettez à jour la source de données de manière à les inclure.
Utilisation de sources de données publiées dans votre flux
Pour vous connecter à une source de données publiée et l’utiliser dans votre flux, suivez les instructions de votre version de Tableau Prep :
Tableau Prep Builder à partir de la version 2020.2.2 et sur le Web
Vous pouvez vous connecter à des sources de données publiées et à d’autres sources qui sont stockées sur Tableau Server ou Tableau Cloud directement depuis le volet Connexion. Si vous avez activé le module Data Management(Le lien s’ouvre dans une nouvelle fenêtre) avec Tableau Catalog, vous pouvez également rechercher des bases de données et des tables et vous y connecter. Vous pouvez également afficher ou filtrer par métadonnées des sources de données, par exemple les descriptions, les avertissements sur la qualité des données et les certifications.
Pour plus d’informations sur Tableau Catalog, consultez « À propos de Tableau Catalog » dans l’aide de Tableau Server(Le lien s’ouvre dans une nouvelle fenêtre) ou Tableau Cloud(Le lien s’ouvre dans une nouvelle fenêtre).
Ouvrez Tableau Prep Builder et cliquez sur le bouton Ajouter une connexion .
Dans la création Web, depuis la page d’accueil, cliquez sur Créer > Flux, ou depuis la page Explorer, cliquez sur Nouveau > Flux. Cliquez ensuite sur Se connecter aux données.
Dans le volet Connexion, sous Rechercher des données, sélectionnez Tableau Server.
Identifiez-vous pour vous connecter à votre serveur ou à votre site.
Dans la création Web, la boîte de dialogue Rechercher des données s’ouvre pour le serveur auquel vous êtes connecté.
Dans la boîte de dialogue Rechercher des données, effectuez une recherche dans la liste des sources de données publiées disponibles. Utilisez l’option de filtre pour filtrer par type de connexion et sources de données certifiées.
Sélectionnez la source de données à utiliser, puis cliquez sur Connexion.
Si vous n’êtes pas autorisé à vous connecter à une source de données, la ligne et le bouton Connexion s’affichent en grisé.
Remarque : la liste déroulante Type de contenu ne s’affiche pas si vous n’avez pas activé le module Data Management avec Tableau Catalog. Seules les sources de données publiées sont affichées dans la liste.
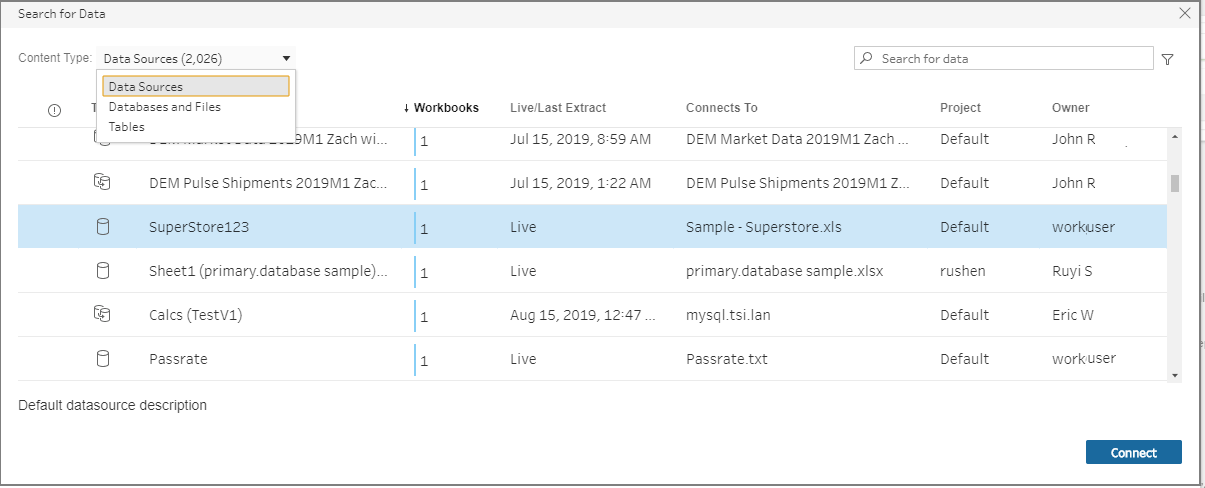
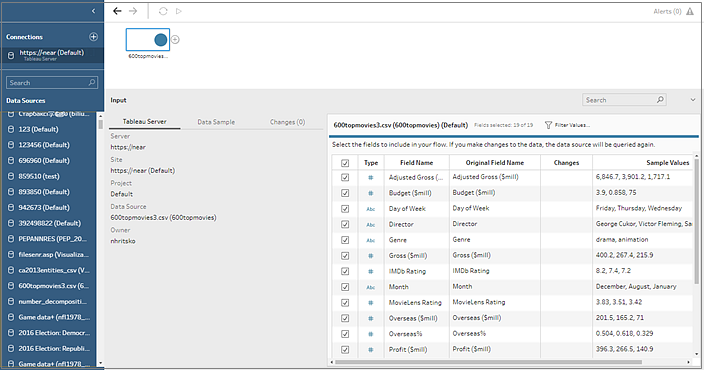
Le source de données est ajoutée au volet Flux. Dans le volet Connexions, vous pouvez sélectionner d’autres sources de données ou utiliser l’option de recherche pour trouver votre source de données et la faire glisser vers le volet Flux afin de créer votre flux. L’onglet Tableau Server dans le volet Entrée affiche des détails sur la source de données publiée.
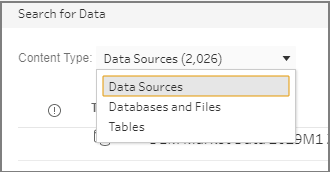
(Facultatif) Si vous avez activé le module Data Management avec Tableau Catalog, utilisez la liste déroulante Type de contenu pour rechercher des bases de données et des tables.
Vous pouvez utiliser l’option de filtre dans le coin supérieur droit pour filtrer vos résultats par type de connexion, avertissements sur la qualité des données et certifications.
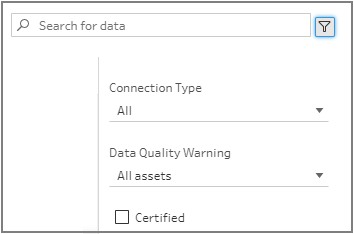
Tableau Prep Builder version 2020.2.1 et versions antérieures
Ouvrez Tableau Prep Builder et cliquez sur le bouton Ajouter une connexion .
Dans la liste des connecteurs, sélectionnez Tableau Server.

Identifiez-vous pour vous connecter à votre serveur ou à votre site.
Sélectionnez votre source de données ou utilisez l’option de recherche pour trouver votre source de données et faites-la glisser vers le volet de flux pour démarrer votre flux. L’onglet Tableau Server dans le volet Entrée affiche des détails sur la source de données publiée.
Se connecter aux connexions virtuelles
Pris en charge dans Tableau Prep Builder à partir de la version 2021.4.1 et dans Tableau Server et Tableau Cloud à partir de la version 2021.4. Data Management est nécessaire pour utiliser cette fonctionnalité.
Vous pouvez vous connecter aux données en utilisant des connexions virtuelles pour vos flux. Les connexions virtuelles sont une ressource partageable qui fournit un point d’accès central aux données.
À prendre en compte lorsque vous vous connectez à des connexions virtuelles :
- Les informations d’identification de la base de données sont intégrées dans la connexion virtuelle. Il vous suffit de vous connecter à votre serveur pour accéder aux tables dans la connexion virtuelle.
- Les politiques des données qui appliquent la sécurité au niveau des lignes peuvent être incluses dans la connexion virtuelle. Seuls les tables, champs et valeurs auxquels vous avez accès sont affichés lorsque vous utilisez et exécutez vos flux.
- La sécurité au niveau des lignes dans les connexions virtuelles ne s’applique pas à la sortie de flux. Tous les utilisateurs ayant accès à la sortie de flux voient les mêmes données.
- SQL personnalisé et SQL initial ne sont pas pris en charge.
- Les paramètres ne sont pas pris en charge. Pour plus d’informations sur l’utilisation des paramètres dans votre flux, consultez Créer et utiliser des paramètres dans les flux.
Pour plus d’informations sur les connexions virtuelles et les stratégies de données, consultez Tableau Server(Le lien s’ouvre dans une nouvelle fenêtre) ou Tableau Cloud(Le lien s’ouvre dans une nouvelle fenêtre).
Ouvrez Tableau Prep Builder et cliquez sur le bouton Ajouter une connexion .
Dans la création Web, depuis la page d’accueil, cliquez sur Créer > Flux, ou depuis la page Explorer, cliquez sur Nouveau > Flux. Cliquez ensuite sur Se connecter aux données.
Dans le volet Connexion, sous Rechercher des données, sélectionnez Tableau Server.
Identifiez-vous pour vous connecter à votre serveur ou à votre site.
Dans la création Web, la boîte de dialogue Rechercher des données s’ouvre pour le serveur auquel vous êtes connecté.
Cliquez sur Type | Tous.

Sélectionnez Connexions virtuelles.

Sélectionnez la source de données à utiliser, puis cliquez sur Connexion.
Le source de données est ajoutée au volet Flux. Dans le volet Connexions, vous pouvez faire votre sélection dans la liste des tables incluses dans la connexion virtuelle et les faire glisser vers le volet Flux pour commencer votre flux.
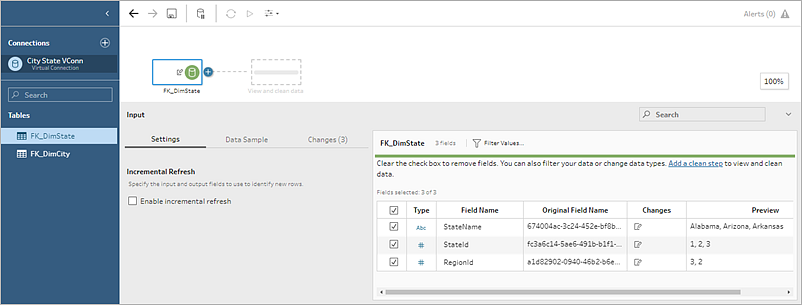
Remarque : si vous voyez des opérations Renommer dans le volet Modifications lors de la connexion à une connexion virtuelle, ne les supprimez pas. Tableau Prep génère automatiquement ces opérations pour lesquels créer un mappage et afficher le nom convivial du champ.
Vous pouvez vous connecter à un extrait de données en tant qu’entrée pour votre flux de données. Les extraits sont des sous-ensembles de données enregistrés que vous pouvez créer en utilisant des filtres et en configurant d’autres limites. Les extraits sont enregistrés sous forme de fichiers .hyper.
Pour plus d’informations sur l’enregistrement et l’utilisation d’extraits avec Tableau Prep Builder, consultez Enregistrer et partager votre travail.
Se connecter aux données via Tableau Catalog
Si vous avez activé le module Data Management(Le lien s’ouvre dans une nouvelle fenêtre) avec Tableau Catalog, vous pouvez également rechercher des bases de données, des fichiers et des tables stockés dans Tableau Server ou Tableau Cloud, et vous y connecter.
Pour plus d’informations sur Tableau Catalog, consultez « À propos de Tableau Catalog » dans l’aide de Tableau Server(Le lien s’ouvre dans une nouvelle fenêtre) ou Tableau Cloud(Le lien s’ouvre dans une nouvelle fenêtre).
Autres options de connexion
Lorsque vous vous connectez, vous pouvez également voir les options suivantes, selon la connexion que vous choisissez.
Utiliser SQL personnalisé pour la connexion aux données
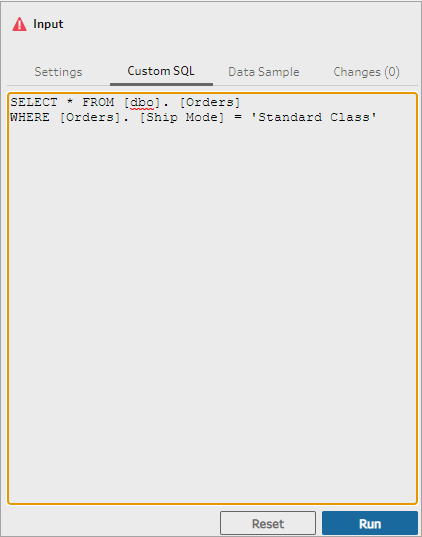
Si vous connaissez exactement les informations dont vous avez besoin à partir d’une base de données et que vous maîtrisez l’écriture des requêtes SQL, vous pouvez utiliser des requêtes SQL personnalisées pour vous connecter aux données comme vous le faites dans Tableau Desktop. Vous pouvez utiliser SQL personnalisé pour réunir vos données à travers plusieurs tables, remanier des champs afin de réaliser des jointure entre bases de données, restructurer ou réduire la taille de vos données à analyser, etc.
Connectez-vous à votre source de données et, dans le volet Connexions du champ Base de données, sélectionnez une base de données.
Cliquez sur le lien SQL personnalisé pour ouvrir l’onglet SQL personnalisé.
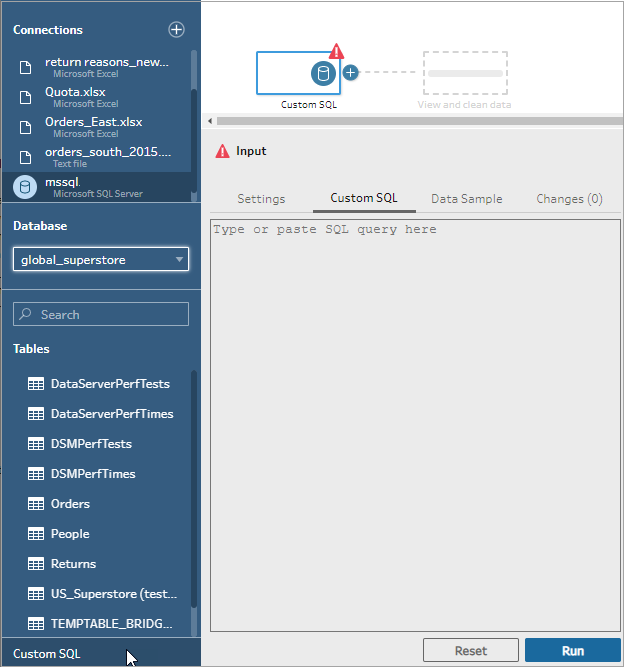
Saisissez ou collez la requête dans la zone de texte, puis cliquez sur Exécuter pour exécuter votre requête.
- Ajoutez une étape de nettoyage dans le volet Flux de manière à ce que seuls les champs pertinents de la requête SQL personnalisée soient ajoutés à votre flux.
Utiliser SQL initial pour interroger vos connexions
Pris en charge dans Tableau Prep Builder à partir de la version 2019.2.2 et lors de la création de flux sur le Web à partir de la version 2020.4.1.
Vous pouvez spécifier une commande SQL initiale qui s’exécutera lors de la connexion à la base de données qui la prend en charge. Par exemple, lorsque vous vous connectez à Amazon Redshift, vous pouvez entrer une instruction SQL pour appliquer un filtre lors de la connexion à la base de données de la même manière que vous ajoutez des filtres à l’étape des données entrantes. La commande SQL s’appliquera avant que les données soient échantillonnées et chargées dans Tableau Prep.
Depuis Tableau Prep Builder (version 2020.1.3) et sur le Web, vous pouvez également inclure des paramètres pour transmettre les données de nom d’application, de version et de nom du flux et ainsi inclure des données de suivi lorsque vous interrogez votre source de données.
Pour actualiser vos données et exécuter à nouveau la commande SQL initiale, effectuez l’une des opérations suivantes :
- Modifiez la commande SQL initiale et actualisez l’étape des données entrantes en procédant à une nouvelle connexion.
- Exécutez le flux. La commande SQL initiale est exécutée avant le traitement de toutes les données.
- Exécutez le flux sur Tableau Server ou Tableau Cloud. La commande SQL initiale est exécutée à chaque fois que le flux est exécuté dans le cadre du chargement des données
Remarque : le module Data Management(Le lien s’ouvre dans une nouvelle fenêtre) est nécessaire pour exécuter votre flux sur Tableau Server ou Tableau Cloud. Pour plus d’informations sur Data Management, consultez À propos de Data Management(Le lien s’ouvre dans une nouvelle fenêtre).
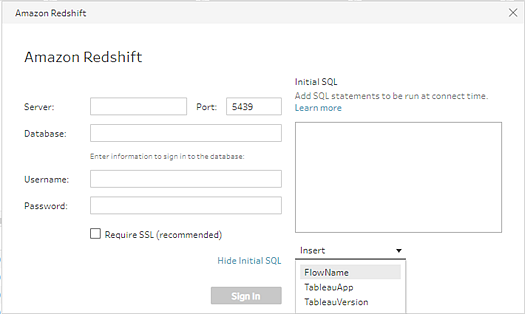
- Dans le volet Connexions, sélectionnez, dans la liste, un connecteur prenant en charge SQL initial.
- Cliquez sur le lien Afficher SQL initial pour développer la boîte de dialogue et entrer vos instructions SQL.
Inclure des paramètres dans votre expression SQL initiale
Pris en charge dans Tableau Prep Builder à partir de la version 2020.1.3 et lors de la création de flux sur le Web à partir de la version 2020.4.1.
Vous pouvez transmettre les paramètres suivants à votre source de données pour ajouter des détails supplémentaires concernant votre application Tableau Prep, la version et le nom du flux. Les paramètres TableauServerUser et TableauServerUserFull ne sont pas pris en charge actuellement.
| Paramètre | Description | Valeur retournée |
|---|
| TableauApp | L’application utilisée pour accéder à votre source de données. | Prep Builder Prep Conductor |
| TableauVersion | Le numéro de version de l’application. | Tableau Prep Builder : renvoie la version exacte. Par exemple : 2020.4.1 Tableau Prep Conductor : renvoie la version majeure du serveur où Tableau Prep Conductor est activé, Par exemple : 2020.4 |
| FlowName | Le nom du fichier .tfl dans Tableau Prep Builder | Exemple : Entertainment Data_Cleaned |